AI — это мир парадоксов. Мир миллиардов инвестиций и самых быстрорастущих стартапов. При всём этом блеске больше 80% компаний ничего не зарабатывают от внедрения AI и более 80% AI-проектов проваливаются, не дойдя до внедрения. Мне кажется, число ближе к 100%.
Главная причина — нехватка опыта разработки проектов с использованием LLM. Мы невероятно круто научились разрабатывать ИТ-проекты, ввели столько методологий, что только по искусству ведения ИТ-проектов делают отдельные курсы. В AI-проектах нам тоже пора строить методологии.
Я уже 3 года разбираюсь, как жить в согласии с LLM, и расписал весь свой опыт разработки в 12 правилах. Правил, которые позволят сэкономить тонну нервов, времени и денег. Устраивайтесь поудобнее — мы начинаем делать ваш LLM-проект.
Правило 1. Четыре этапа в LLM-проекте
Любой LLM-проект должен последовательно пройти 4 этапа.
- Бизнес-постановка. Здесь мы формируем целеполагание, какую фичу хотим сделать. На какие ключевые метрики хотим повлиять. Главное: не стоит заранее думать про техническое решение, которое больше всего сейчас на хайпе. Фиксируем бизнес-ожидания от проекта, но технику делаем уже дальше.
- Создание прототипа. Проблема подавляющего большинства AI-проектов: когда начинается разработка, никто не понимает, что надо сделать. И начинают выдумывать на ходу — когда надо не выдумывать, а уже делать. Цель прототипа — получить продуктовый ориентир, что наша система должна уметь. При этом там могут быть какие угодно большие модели, он может работать час на запрос. Не ругайте его. Он исправится на следующем этапе. Признак успеха этого этапа: человек, который делал бизнес-постановку, скажет «вот сделайте такое, только быстро, и я буду счастлив».
- Разработка. Здесь мы ускоряем прототип, делаем его более дешёвым, опираясь на прототип из пункта 2. На этом этапе технические специалисты улучшают LLM: уменьшают в размерах, включают нужные оптимизации, дообучают модель и т. д. В итоге у нас получается LLM, которая проходит все наши требования, и мы готовы её использовать.
- Деплой и мониторинг качества. Здесь пишется сервис, в котором работает наша LLM-система. Важно, что нам нужно контролировать качество этого сервиса. Причём не разово, а постоянно. Зачем? Во-первых, мы могли где-то набагать при написании сервиса. Во-вторых, мы можем набагать попозже. И ещё есть distribution shift, когда пользователи с течением времени по-другому пользуются системой, и она начинает хуже работать.

Мы должны последовательно пройти 4 этапа. Цель 2-го этапа — сделать прототип, который устраивает нас по качеству. Цель 3-го этапа — снять все другие ограничения внедрения (безопасность, скорость, время ответа и т. д.).
Правило 2. Сначала настройте метрики качества
Бизнес-постановку сделали. С чего начинать делать прототип? С метрик качества.
В LLM-разработке, как и в обычной продуктовой, успех зависит от того, как быстро вы умеете итерироваться. Хорошие метрики качества = быстрые итерации.
Понятно, что вас волнуют пользовательские онлайн-метрики. Желательно — деньги. Ну или retention пользователей. К сожалению, их долго мерить. Для быстрых итераций нам нужны офлайн-метрики качества, которые как-то аппроксимируют целевые.
Разные классы задач оценивают по-разному
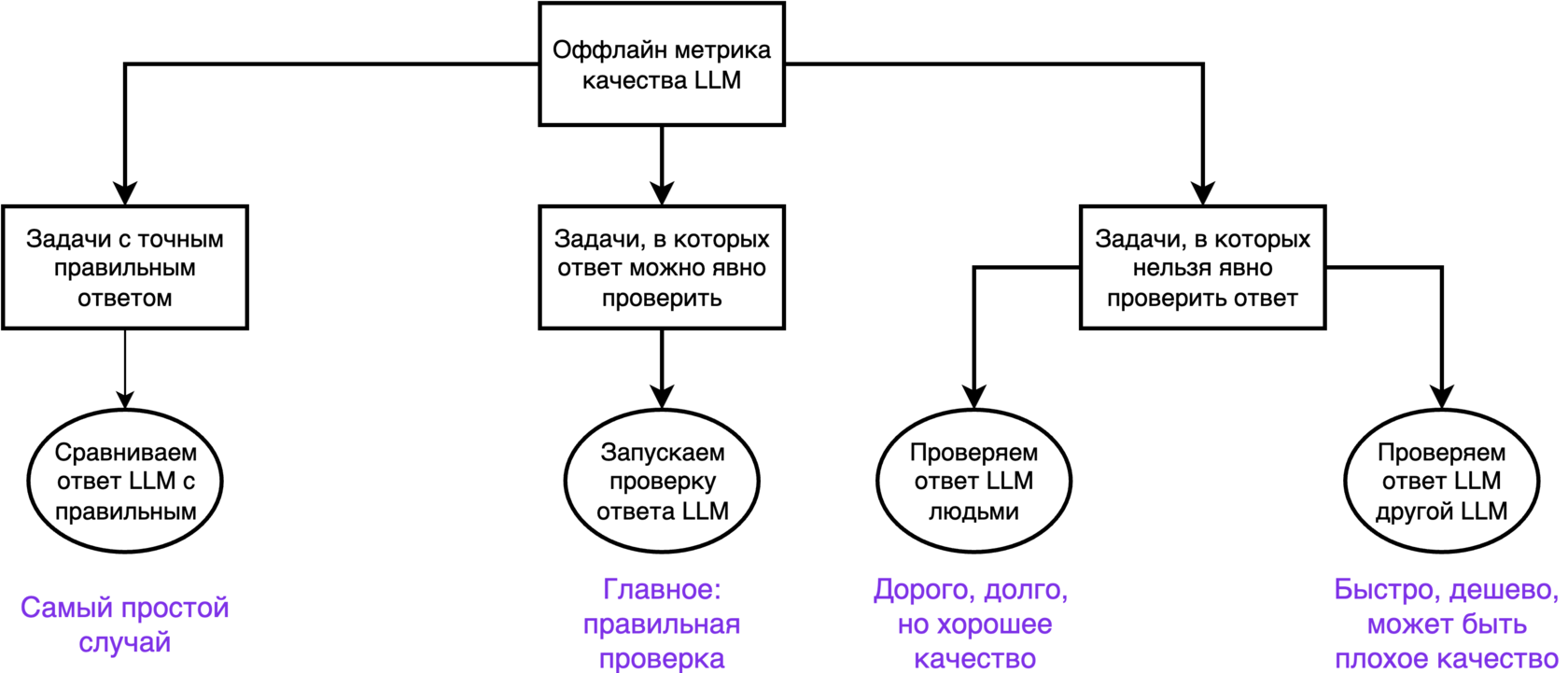
Есть 3 класса задач. В них по-разному делаются офлайн-метрики качества.
- Задачи, в которых есть точный ответ. Тогда все ваши метрики — это сравнение ответа модели с эталоном. Например, классификация, где вы сравниваете с правильным классом. Сравнивать можно не обязательно точным совпадением. Можно, например, текстовыми метриками (BLEU, WER) или пускай сравнивает отдельная модель, например, BERT (bert_score). В этом классе обычно проблем нет.
- Задачи, в которых ответ можно проверить. Ну тогда возьмите и проверьте. Это, в первую очередь, код, который можно прогнать на тестах. Это математика, в которой можно проверить формальное доказательство. В этом классе раньше были проблемы, сейчас современный RL тут всем показывает класс. Посмотрите, сколько разных компаний выигрывают одну и ту же олимпиаду по математике.
- Задачи, в которых правильный ответ непонятно какой. С этим обычно самые трудности. И обычно здесь лежат все интересные LLM-задачи. Делаем RAG-ассистента, человек задаёт вопрос, мы что-то ответили. Ответить можно миллионом способов, верифицировать нельзя.
Два варианта оценки LLM
- Размечаем людьми. Кто-то называет их AI-тренерами или асессорами. Объясняете им продуктовые критерии. Это объяснение может быть довольно длинным: посмотрите пример 180-страничной инструкции оценки качества поиска Google. Важно: контроль качественной разметки — сложная операционная задача. Кто-то может халтурить, читерить, забывать правила.
- LLM-as-a-judge. У нас нет денег/времени работать с людьми. Делаем LLM, которая оценивает ответы другой LLM. Критиковать чужой труд всегда проще.
Для несложных разметок завести LLM-as-a-judge обычно получается. Для чего-то сложного/экспертного лучше обращаться к людям.
Правило 3. Пять инструментов работы с LLM
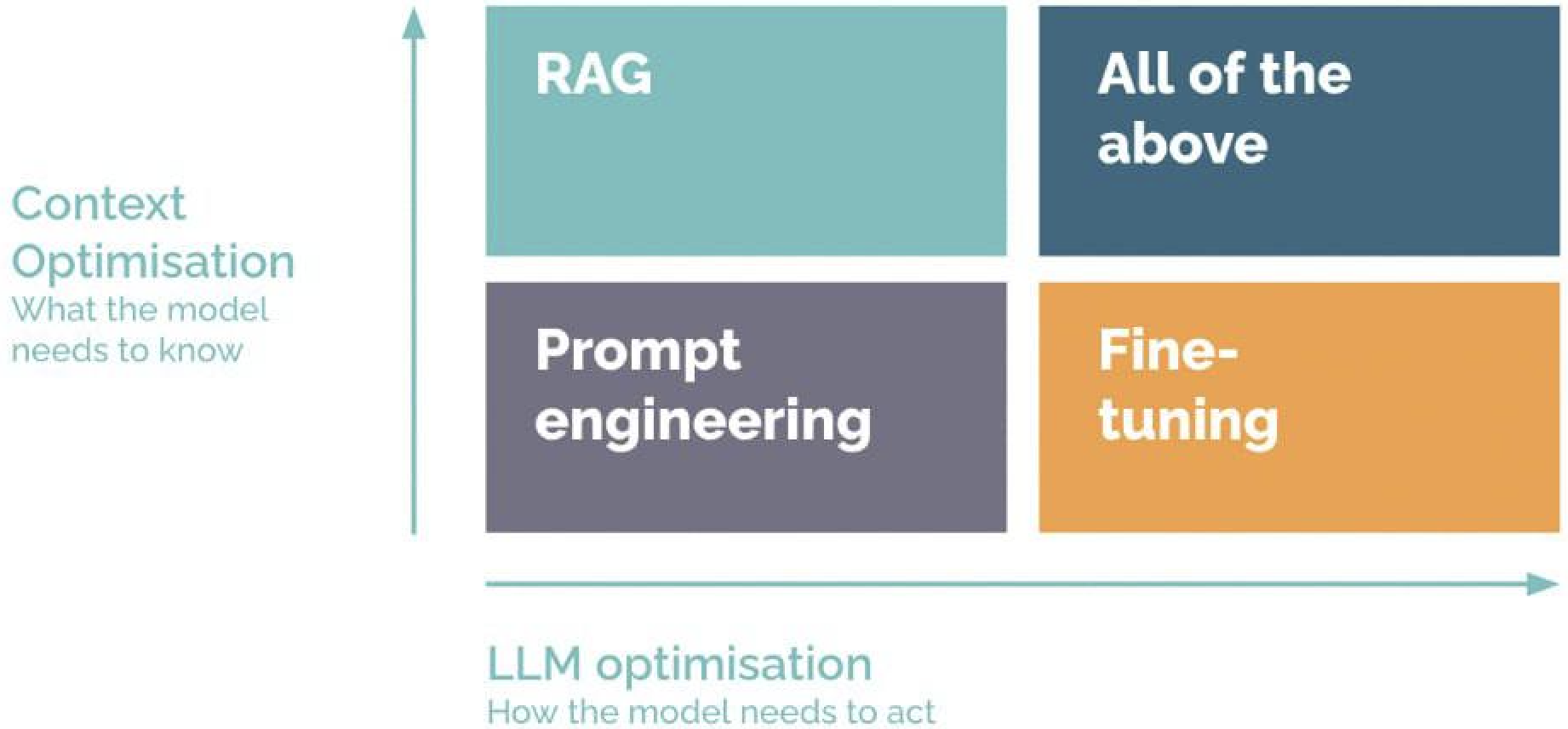
Не так много способов сделать LLM работать лучше. Вам нужно знать каждый из них и понимать, когда какой применять.
- Изменение промпта. С этого всегда надо начинать. Удивительно, но часто делать больше ничего не надо. Не стоит сходить с ума и обещать LLM 100 долларов за правильный ответ. Базовые правила: пишите подробно и с точными формулировками, пробуйте Few-Shot, используйте reasoning или Chain of Thoughts, используйте Structured Output, дробите большую задачу на подзадачи. Все эти техники можно прочитать в учебнике.
- RAG. Подключение LLM к внешней базе знаний. Основной способ внести в LLM знания, которые она не получила во время обучения. Тут все сразу думают про RAG как какой-то поиск по векторному хранилищу. Это не так.
- Дообучение. Вы собираете данные под вашу задачу. Меняете параметры LLM, чтобы она как можно лучше подстроилась под эти данные. Нужно использовать, когда не получается объяснить LLM, что вы от неё хотите, через промпт.
- Инструменты. Странно просить LLM в уме умножить два трёхзначных числа. Логичнее научить её пользоваться калькулятором. С помощью такого трюка можно научить LLM делать кучу вещей: узнавать информацию из поиска, писать по электронной почте, извлекать данные из SQL-таблиц.
- Агентность. Агенты — это LLM-системы, которые сами определяют своё поведение, контролируя, как они выполняют поставленную задачу. Их нужно применять, когда задача плохо поддаётся точному регламенту. Подробнее в Правиле 7.
Резюме по 5 инструментам
Всегда нужно начинать с промптинга. RAG стоит использовать для добавления знаний в LLM. Дообучение — когда промпт не позволяет достичь ожидаемого поведения. Инструменты позволят LLM решать задачи, которые выходят за рамки написания текстов. Наконец, агенты помогут решать задачи, для которых сложно написать точный порядок действий.
Правило 4. До разработки всегда делайте прототип
Как делают обычно: придумали, как с помощью LLM увеличить бизнес-метрику, и пошли раздавать задачи инженерам. Мол, идите данные собирать да модели обучать.
Почему нельзя сразу делать
В AI сложно спрогнозировать достижимость эффекта. Легко может оказаться, что текущими технологиями ваша задача не решается с нужным качеством. Но узнаете вы это спустя полгода, когда инженеры принесут модель.
В AI множество краевых случаев. Заранее прописать весь список в техническом задании невозможно. Но спустя полгода вы можете очень удивиться, что модель работает не так, как вы предполагали.
Что такое прототип
Это система, которая имеет необходимое качество, но которую нельзя использовать по другим причинам. Например, очень долго работает. Или не проходит по требованиям безопасности. Главное — вам должен нравиться тот результат, который она даёт. Прототип обычно создаётся на какой-то удобной платформе, типа n8n.
Шаги создания прототипа
- Выделенная команда — менеджер, бэкенд-разработчик, опытный специалист, который собирал LLM-системы.
- Тестовая выборка — для всех входных запросов команда точно понимает, какой правильный ответ.
- Метрики качества на тестовой выборке.
- Итерации, которые максимизируют качество.
По этой методике реально собрать рабочий прототип за несколько недель.
Правило 5. Добавляйте все знания в контекст LLM
LLM нужно много чего знать о вашей задаче, чтобы её решить. Факты о вашем продукте, какие есть инструменты, как зовут пользователя. Всё это надо добавить в промпт. Поэтому его часто называют контекстное окно.
Несмотря на то, что модели всё лучше работают с длинными последовательностями, вам всё равно нужно думать о размере контекстного окна. Чем длиннее окно, тем сложнее модели понять, что вообще тут происходит.
Что такое RAG
Само название метода пришло из статьи 2020 года, где авторы показали, как можно соединить модели с поиском. Сейчас под RAG подразумевают всё, когда к LLM добавляют поиск по внешнему хранилищу информации.
Технически RAG выглядит всегда примерно так:
- LLM формулирует запрос, по которому ей нужна информация во внешней базе.
- По этой базе запускается поиск, находится самый релевантный текст.
- Релевантный текст добавляется в контекст LLM.
- По этому контексту LLM делает генерацию.
Правило 6. Дайте LLM правильные инструменты
Один из самых частых паттернов работы LLM — модель переводит запросы с человеческого языка в вызов нужных инструментов. Очень важно: любую детерминированную логику выполнять инструментом, а не LLM.
Кстати, код — это самый мощный инструмент, который вы только можете дать LLM. Пример: делаем парсер сайтов, который не ломается, когда вёрстка меняется. LLM сначала анализирует разметку сайта, дальше пишет код, который работает конкретно для этого сайта. Смотрите похожий кейс компании Ramp.
Structured Output
Вы выдаёте желаемую схему ответа, а LLM не может при ответе её нарушить. Работает так:
- Ваша схема конвертируется в грамматику.
- Генерация каждого следующего токена жёстко ограничена этой грамматикой.
Structured Output есть у некоторых LLM-провайдеров, а также реализован во многих опенсорс-библиотеках.
Как научить LLM использовать инструменты
- Добавить в промпт описание этого инструмента: как его вызывать, какие входные аргументы, что он возвращает.
- Дообучить LLM правильно инструмент использовать. Делать только, если 1-й пункт не сработал. Про это есть классическая статья.
Правило 7. Автономные агенты — крайне редкий зверь
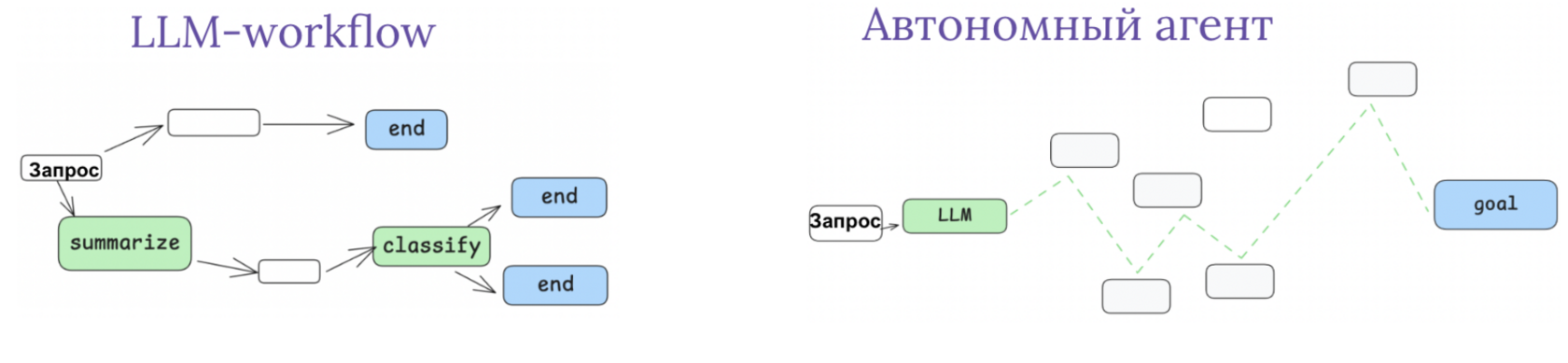
Есть 2 разных архитектуры LLM-систем, которые отличаются тем, насколько много свободы вы даёте системе.
LLM-workflow
Вы сами решаете, какую последовательность действий надо совершить, чтобы решить задачу. И эту последовательность программируете. LLM вызываете только в конкретных местах программного кода, где нужна недетерминированная логика.
Плюсы:
- Предсказуемость — вы точно знаете в каждый момент времени, что должно происходить.
- Легко улучшать — на каждом этапе можно посчитать метрики качества.
- Быстро работает — когда LLM решает одну конкретную задачу, она может не быть очень большой и дорогой.
Минус один: чем сложнее исходная задача, тем больше логики вам нужно будет запрограммировать, тем чаще всё будет ломаться.
Автономные агенты
Мы не хотим сами программировать всю логику. Хотим, чтобы LLM сама решила, как решать задачу. Мы пишем в промпте для LLM, что она должна сделать, рассказываем, какие доступны инструменты. Дальше LLM должна составить план действий, совершать нужные действия и в итоге решить задачу.
Плюсы:
- Возможность решать задачи, которые сложно описать алгоритмом.
- Скорость разработки — здесь мы только пишем инструменты и промпт.
Минусы:
- Пока очень ненадёжно — LLM пишет планы, рефлексирует, использует инструменты, что-то из этого точно сломается.
- Очень дорого и долго работает — нужно использовать самые большие рассуждающие модели.
Я знаю 3 примера, в которых можно с ненадёжностью успешно бороться:
- Агент для разработки кода. Результат проверяется системой тестирования.
- Агент для поиска информации. Агент исследует интернет, человек перепроверяет.
- Персональный агент-ассистент. Все рискованные операции подтверждаются у человека.
Правило 8. Проверяйте ответы другими моделями
Часто по ответу модели можно догадаться, что что-то пошло не так. Нам нужно построить модель-критика, которая посмотрит на ответ LLM и догадается, что что-то пошло не так.
Как строить критика
- Через рефлексию. Критик смотрит на ответ LLM, на её исходную задачу, на план — и независимо разбирается, всё ли правильно.
- Через оценку качества. LLM-as-a-judge оценивает качество ответа. Если оно сильно ниже среднего — ответ стоит исправить.
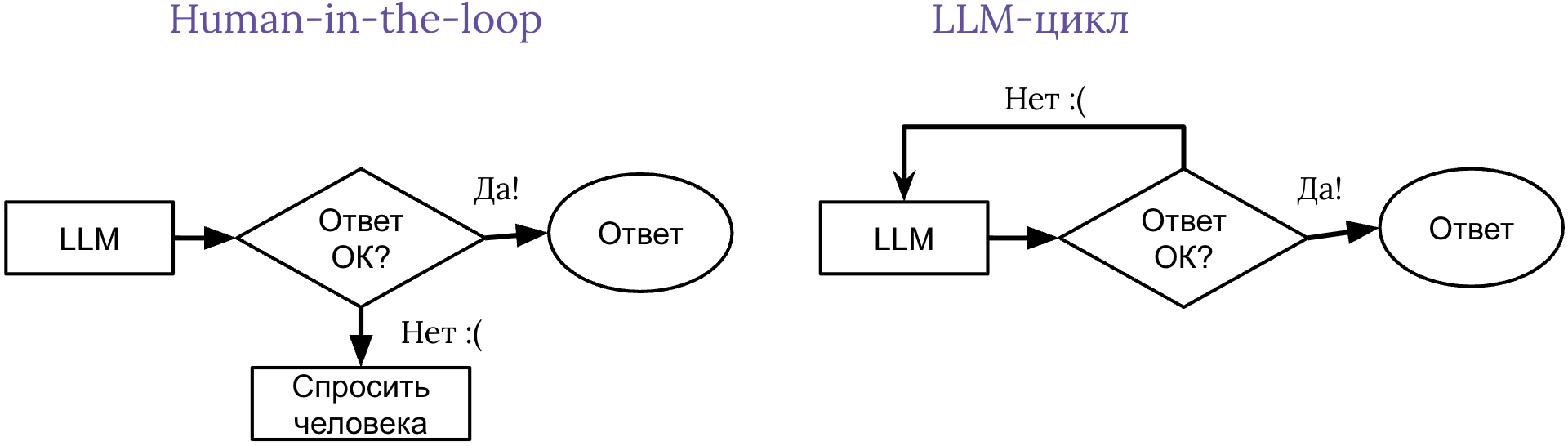
Как чинить найденные проблемы
- Human-in-the-loop. Переводим запрос на человека. Самый распространённый метод внедрения AI: сложные задачи обрабатывают люди, рутинные — LLM.
- LLM-цикл. Отправляем LLM на пересдачу. Показываем LLM, что именно нашёл критик. LLM, используя конструктивную критику, переделывает задачу.
Если есть возможность, я всегда рекомендую использовать human-in-the-loop даже в небольшом объёме.
Правило 9. Часто можно обойтись моделями поменьше
Можно выделить 3 качества моделей, которые раскрываются с увеличением числа параметров.
- Знания о мире. Модель становится энциклопедией. Чем больше параметров, тем больше информации она может заполнить.
- Рассуждения. Способность модели генерировать рассуждения и делать на основании них выводы.
- Следование промпту. Насколько модель быстро схватывает, что от неё хотят.
Очень хорошая новость: для многих задач не нужны 1 и 2. Отсутствие знаний решается RAG. Рассуждения часто избыточны в рутинной работе. Можно взять небольшую LLM (1–10 миллиардов параметров) и побороться с проблемой 3 — об этом следующее правило.
Правило 10. Дообучайте LLM, только когда это реально нужно
Дообучать модель стоит тогда, когда модель не слушается вашего промпта. Например, галлюцинирует в задаче RAG. Эту проблему можно починить дообучением.
Дообучение фокусирует модель. LLM обучалась на всём интернете для решения сразу множества задач. Нужно ей объяснить, как она должна решать только одну вашу задачу.
Важно: фокусируя небольшую модель на одной задаче, вы можете добиться качества лучше, чем самые большие модели OpenAI. В статье коллеги взяли 31 задачу, дообучили модели и получили в среднем на 10% лучше, чем GPT-4, при числе параметров в 1000 раз меньше.
Важно. Дообучение — рисковая операция. Неправильное дообучение может заставить модель галлюцинировать (см. статью коллег из Google). Обращайтесь к профессионалам.
Правило 11. Не забудьте включить все оптимизации
Помимо уменьшения числа параметров, есть огромное число вариантов удешевления и ускорения LLM. Самые популярные библиотеки:
- vLLM
- SGLang
- TensorRT-LLM
- llama.cpp
- TGI
Самые важные оптимизации:
- Батчевание. Группирует запросы в LLM в один пакет. Чем больше размер батча, тем эффективнее GPU.
- Квантизация. Представление параметров модели в более компактной форме.
- Кеширование. Запоминаем ответ LLM на промпт. Ещё есть KV-кеширование.
- Спекулятивный декодинг. Маленькая модель предсказывает несколько токенов, оригинальная — верифицирует.
- Эффективные вычисления. Flash Attention, Paged Attention и т. д.
Правило 12. Двигайтесь итеративно через анализ проблем
Это последнее 12-е правило, которое рассказывает, как применять все остальные.
Очень часто проект сразу начинают с прицелом на космолёт. Заранее продумывают сложнейшую архитектуру и начинают долго-долго её делать. По итогу 95% всей этой разработки отправится на помойку.
Самый рациональный вариант — начинать с MVP, а затем последовательно его усложнять.
Как итеративно улучшать систему
В каждую секунду работы над проектом вы должны понимать, какие сейчас есть проблемы. Эти проблемы надо выписать в один список в порядке важности.
- Собираем корзинку входных задач. Можно собирать через текущий продукт, опросы клиентов или генерируя синтетические примеры LLM.
- Смотрим качество ответов на корзинке. Используем разметку асессорами или LLM-as-a-judge.
- Кластеризуем проблемы. Раскладываем по 2 осям: по тематикам и по причинам поломки.
Далее решаем каждую проблему по шаблону:
- придумываем гипотезу, которая чинит эту проблему
- реализуем эту гипотезу
- считаем метрику качества
- если метрика улучшилась — принимаем гипотезу
Важно. Не пытайтесь тестировать сразу много гипотез — проверяем одну за одной.
Это двенадцатое правило — финальный ключ к успешному внедрению LLM. Настройте метрики качества и, используя итеративный подход, примените всё, что узнали в этой статье. Если остались вопросы, как конкретно в вашем случае внедрить LLM — напишите мне в Telegram, разберём вашу ситуацию.