Каждый день выходят десятки статей с описанием новых архитектур AI-агентов. Пытаться понять в этом шуме, какая архитектура лучше, а какая хуже — тупиковый путь. Вы физически не сможете проверить их все на своих задачах.
Вместо погони за новостями вам необходимо разобраться в фундаментальных принципах: из каких блоков строятся агенты и как эти блоки взаимодействуют между собой. Только так масштабирование AI в компании превращается из хаоса в предсказуемый инженерный процесс. Сборка агентов должна стать похожей на сборку конструктора: вы даёте командам проверенный набор деталей и инструкцию, а они самостоятельно конструируют решения под свои задачи.
Этот подход решает две критические проблемы внедрения:
- Надёжность. Когда вы работаете по системному рецепту, шанс провала кратно снижается. Вы не изобретаете велосипед для каждого нового процесса, а используете проверенные паттерны.
- Стоимость. При использовании стандартизированных блоков внедрение каждого следующего агента обходится дешевле предыдущего. Код, промпты и инструменты переиспользуются. Из одних и тех же кубиков можно собрать и средневековый замок, и космопорт — база одна, цели разные.
В этой статье разберём правила сборки надёжных AI-агентов: из каких блоков они состоят и как их правильно комбинировать, чтобы перейти от единичных экспериментов к массовому внедрению агентских систем.
Из чего состоит надёжный AI-агент
Надёжный агент состоит из 5 функциональных блоков (тело агента) и 2 защитных слоёв, которые обеспечивают безопасность и прозрачность. Разберём их по порядку.
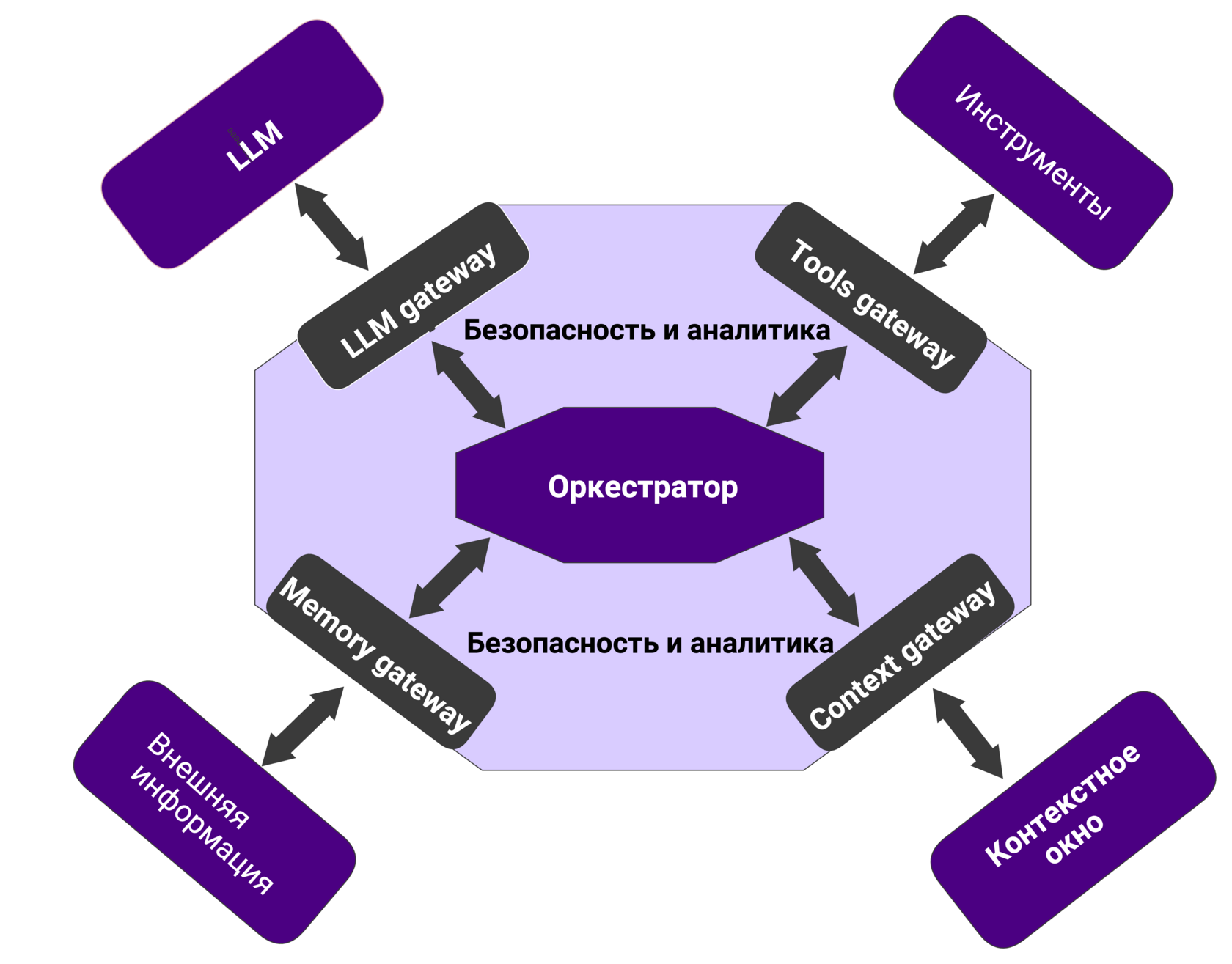
Функциональные блоки
Это блоки, из которых непосредственно состоит сам агент.
1. Оркестратор. Сердце агента. Это runtime-движок, который управляет бесконечным циклом работы агента. Оркестратор запускает все остальные компоненты с нужными аргументами, обрабатывает их выходные данные и, что критически важно, перехватывает ошибки. Он работает по определённому поведенческому шаблону: ReAct (подумай, потом сделай), Plan-Execute (составь план и иди строго по нему).
Физически: Python-код на базе фреймворков вроде LangGraph/LangChain, либо самописное решение на чистом коде.
2. LLM. Мозг агента. Оркестратор собирает контекст и промпт, а затем отправляет их в LLM. Задача «мозга» — не выполнить действие, а принять решение, что делать дальше. В продвинутых системах используется не одна модель, а каскад: дорогие — для сложного планирования, дешёвые и быстрые — для рутинных операций (классификация, парсинг ответов).
Физически: API к облачному провайдеру или локальная модель на ваших серверах.
3. Контекстное окно. Память агента. Управление контекстным окном — одна из сложнейших инженерных задач. Нам нужно, чтобы в момент запуска LLM в её памяти была ровно та информация, которая необходима для текущего шага. Чем больше мусора в контексте, тем выше шанс галлюцинаций.
Физически: алгоритмы управления памятью (сжатие, суммаризация, вытеснение старых диалогов).
4. Внешняя информация. Справочник агента. Здесь лежат данные, которые не нужны в контексте прямо сейчас, но могут потребоваться позже. Это либо внешние файлы (корпоративная база знаний, регламенты, документация), либо информация, которую агент сам решил сохранить в процессе работы.
Физически: просто файлы, доступ к которым происходит через RAG или другие инструменты (вроде утилиты командной строки grep).
5. Инструменты. Руки агента. Это любые внешние программы, которые агент может вызывать для решения задачи: от калькулятора до API банковской системы. Это могут быть как программы на тех же серверах, где запускается агент, так и приложения во внешнем облаке. Можно использовать протокол MCP (Model Context Protocol) для унификации подключений. Важно: инструментом может быть и другой агент. Так появляются мультиагентные системы.
Платформенные слои
Всё взаимодействие функциональных блоков происходит через оркестратор. Но чтобы агент был безопасным и управляемым, мы помещаем оркестратор внутрь двух защитных слоёв.
Любое действие агента — будь то обращение к инструменту, чтение из памяти или запрос к модели — проходит сквозь эти слои через специальные прокси-сервисы, которые называются Gateways (шлюзы). Эти 2 слоя:
1. Безопасность. Каждое действие оркестратора должно проходить премодерацию до исполнения:
- Доступы: имеет ли этот агент право читать данный файл?
- Prompt Injection: нет ли во входящем запросе попытки взломать инструкцию?
- Защита данных: не утекают ли персональные данные клиентов? Их нужно шифровать или маскировать на лету?
2. Аналитика (в агентских системах часто этот слой называют observability — прозрачность). Нам необходимо логировать всё: каждый запуск LLM, каждый вызов инструмента, как менялось состояние памяти. Затем использовать эти данные для оценки качества агента и постоянного мониторинга. Без этого слоя система — чёрный ящик. С ним — у вас есть возможность быстро находить причины ошибок и улучшать качество агента на основе данных.
Далее рассмотрим некоторые компоненты подробнее.
Оркестратор
От выбора оркестратора зависит, будет ли агент вашим надёжным другом или галлюцинирующим кошмаром. Разберём 5 базовых типов, которые нужно применять к разным задачам.
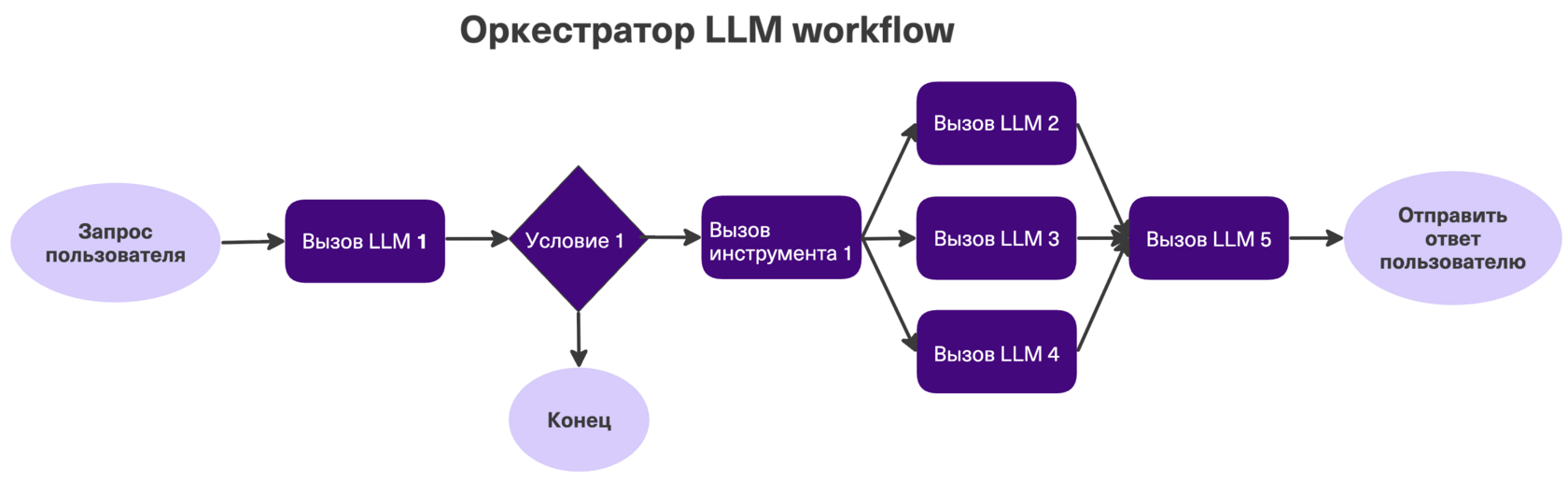
LLM-Workflow (детерминированное исполнение)
Самый надёжный и распространённый вариант в продакшене. Порядок действий жёстко задан разработчиком в коде. LLM здесь используется как функция внутри жёсткого графа: суммаризует ответ, извлекает сущности или классифицирует тексты.
Плюсы: надёжно, предсказуемо, дёшево. Минусы: нужно этот граф написать руками. Для творческих процессов не подходит совсем. Когда использовать: для процессов с высокими рисками и понятным регламентом. Например, умный документооборот, ответы на вопросы клиентов (мы разбирали поддержку курьеров в DoorDash).
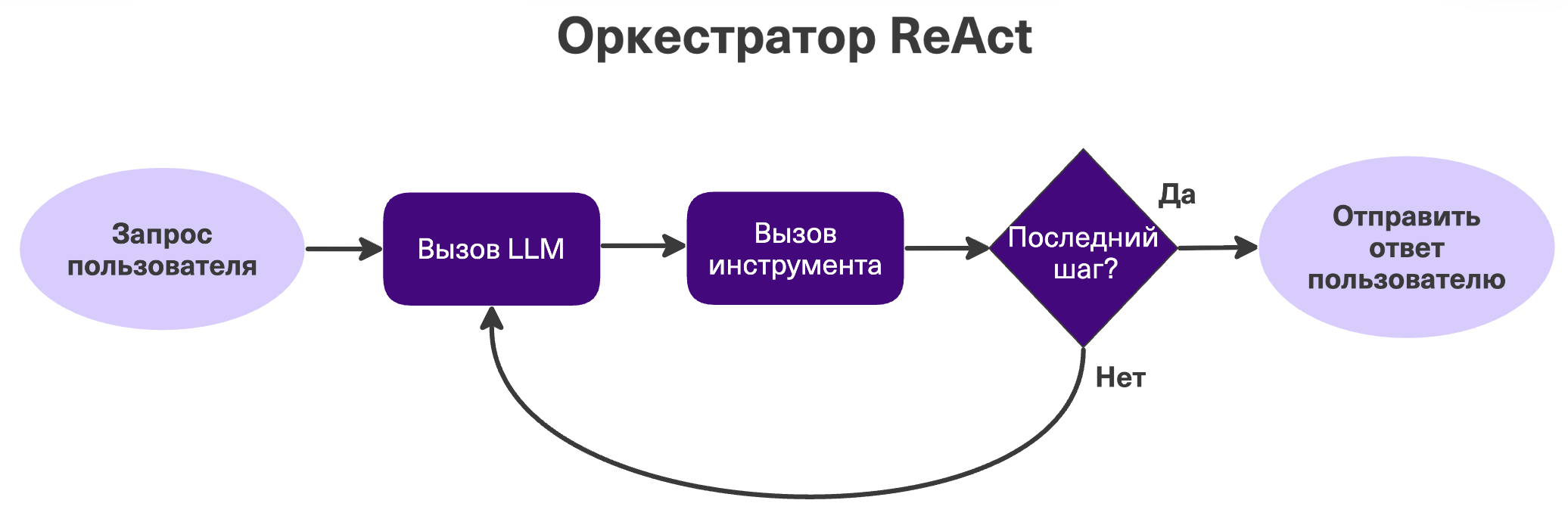
ReAct (рассуждение и выбор действия)
Самый базовый вариант автономного агента. Процесс заранее не зафиксирован. Модель работает в цикле: «Подумал → Выбрал инструмент → Получил результат». Здесь уже сама LLM решает, какой инструмент вызвать и когда остановиться.
Плюсы: гибкость. Может выбирать разные действия под ситуацию. Минусы: часто ломается в долгих задачах (застревает в цикле или забывает цель). Когда использовать: для простых коротких задач с небольшим числом инструментов (например, «найди курс валюты и отправь в Slack»).
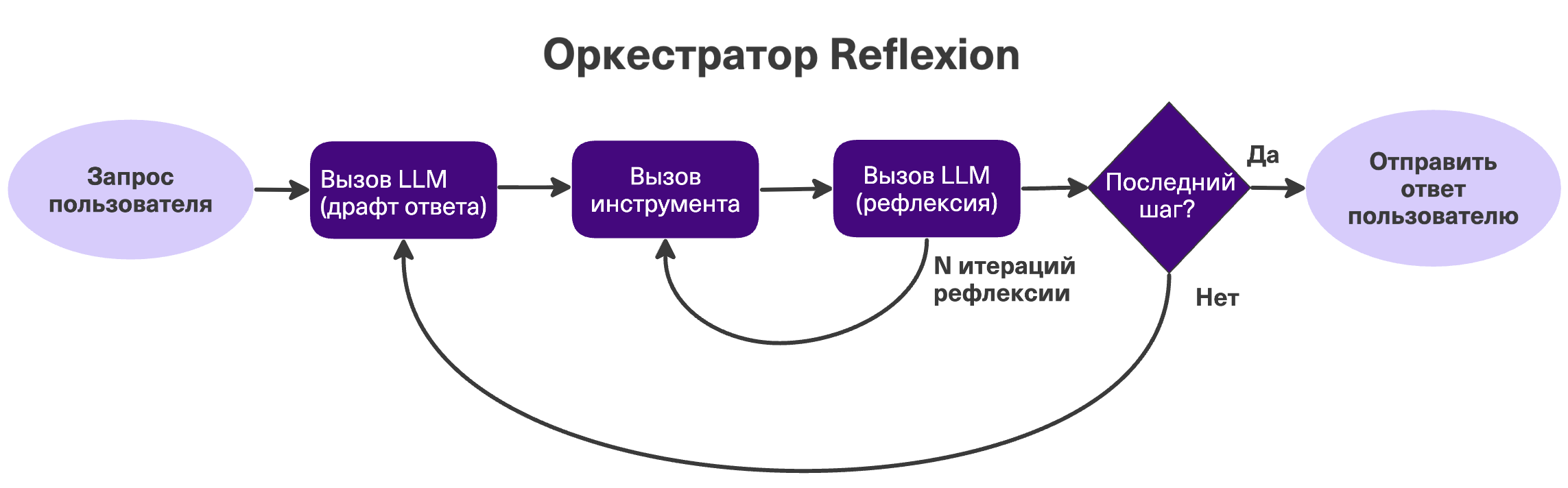
Reflexion (рефлексия)
Умная надстройка над ReAct. В цикл добавляется этап «Рефлексии». Агент получает результат от инструмента, но не бежит дальше, а оценивает: «А то ли я сделал?». Если нет — пересматривает ответ. И так может делать несколько раз для одного действия. Мой любимый паттерн, я тоже мнительный :)
Плюсы: критически поднимает качество в задачах, где результат можно валидировать (код, математика). Минусы: мнительность ест много токенов и замедляет работу. Когда использовать: когда фидбек инструмента максимально полезен. Например, программирование, где фидбек — ошибка выполнения программы.
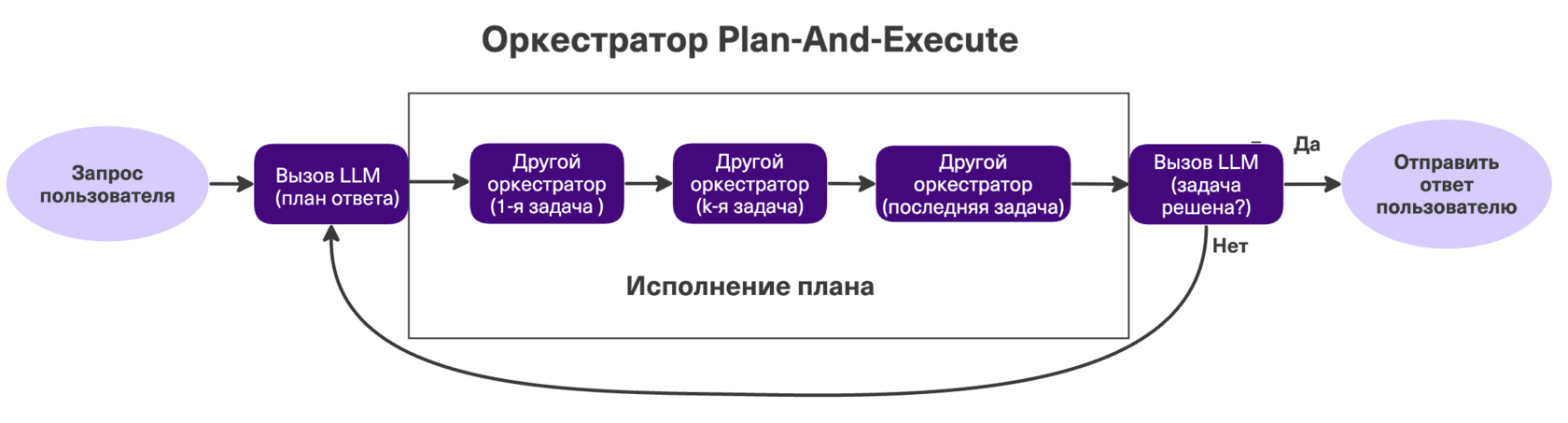
Plan-and-Execute (планирование и исполнение)
Сначала LLM составляет план, затем шаг за шагом другой оркестратор (например, Reflexion) этот план исполняет. Всё работает в едином контекстном окне. Как только план выполнен, LLM проверяет: задача решена или нужно составить новый план?
Плюсы: рабочий вариант решения долгих задач без LLM-Workflow. Минусы: страдает от «распухания» контекста. В истории накапливается столько мусора, что модель ломается. Когда использовать: для длинных цепочек действий, где шаги жёстко зависят друг от друга (любая последовательная аналитика).
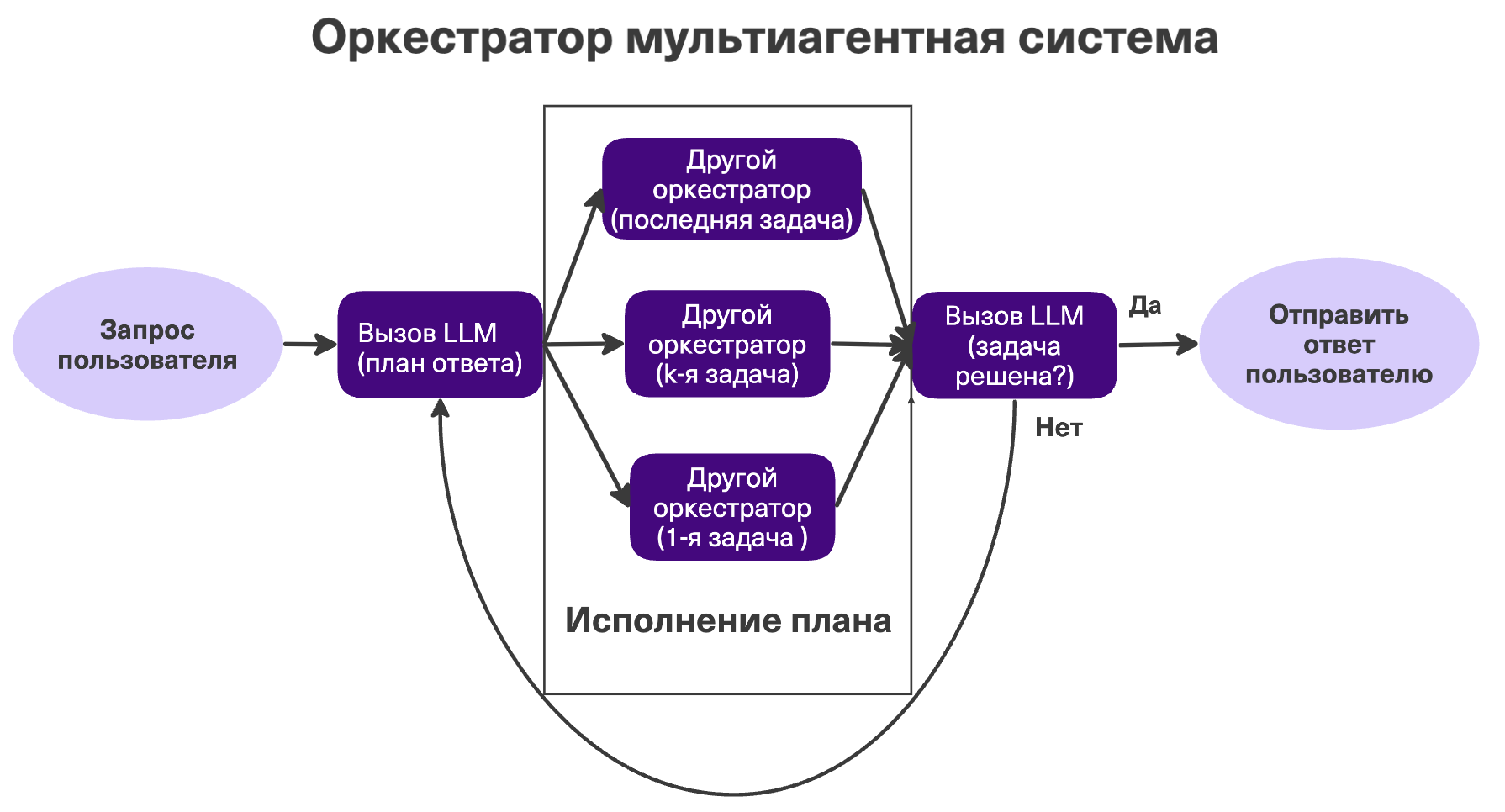
Plan-and-Execute + Мультиагентность
План создаётся как в прошлом пункте, но каждую задачу изолированно решает отдельный оркестратор (субагент). У каждого субагента — своя узкая задача и только необходимая для неё информация, они не делятся контекстом.
Плюсы: мощь планирования + надёжность исполнения. Минусы: можно использовать только для узкого класса задач. Когда использовать: всегда, когда задачу можно разбить на независимые блоки. Например, написание большого отчёта (мы разбирали DeepResearch).
Резюме по оркестрации
Это 5 базовых паттернов. На практике мы их комбинируем. Ваш «агент мечты» может выглядеть как надёжный LLM-Workflow, в узлах которого вызываются более автономные агенты для сложных задач.
Главное правило выбора: берите самую простую архитектуру, способную решить вашу задачу. Если можете написать детерминированный Workflow — напишите и забудьте. За каждую каплю автономности вы платите надёжностью и рисками.
LLM
LLM для агента — это мозг, который принимает решения. В этом разделе обсудим, как должен быть устроен доступ к LLM в компании.
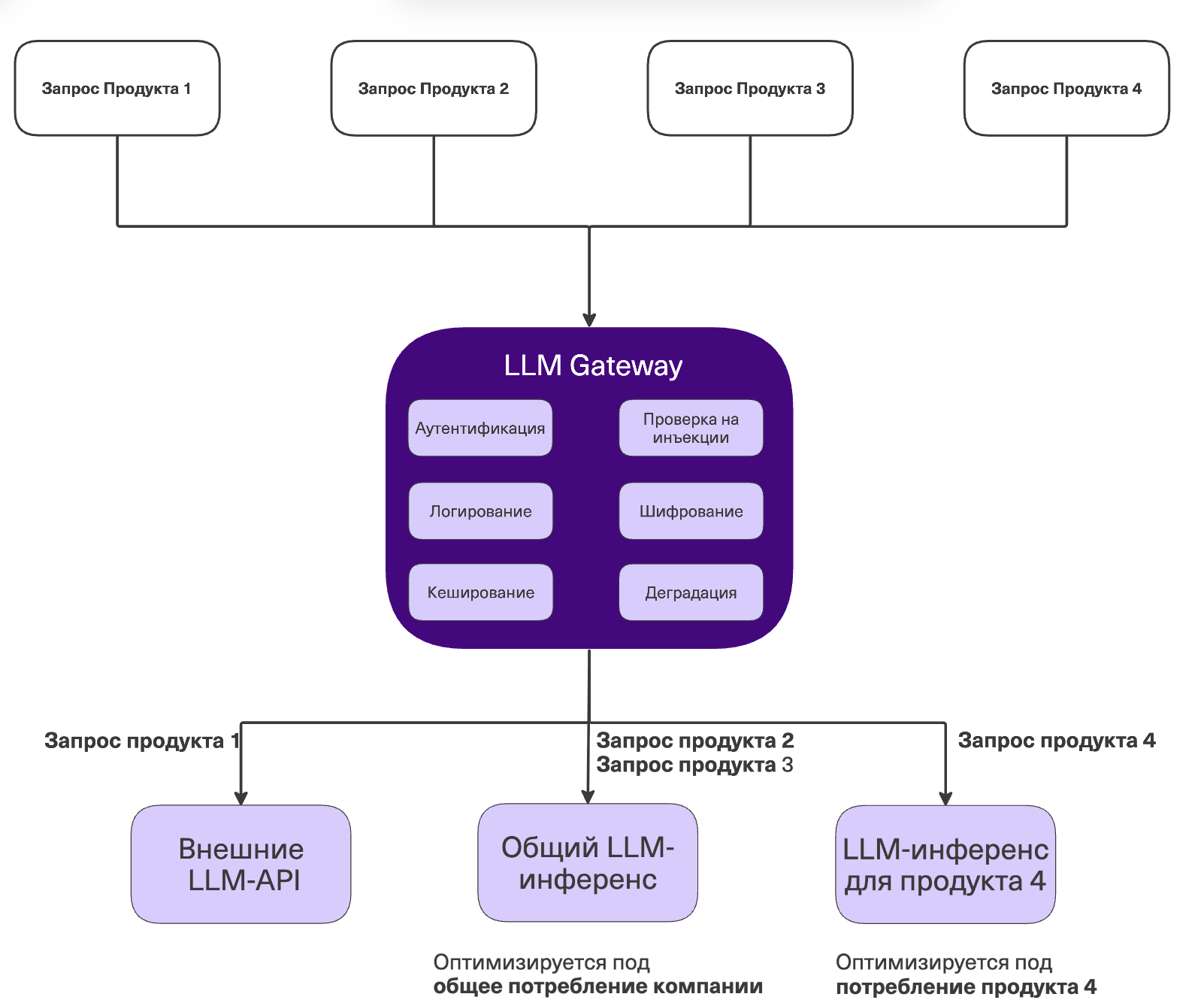
LLM Gateway (шлюз)
Нельзя пускать компоненты агента напрямую к моделям. Все запросы — неважно, к внешней API или к вашей внутренней модели — должны проходить через единый прокси-сервис (Gateway). Клиент общается только с ним. Что должно быть «под капотом» у шлюза:
- Аналитика: логируем, какую модель вызвали, сколько токенов съели и как долго она отвечала. Без этого вы не посчитаете ни health-статус системы, ни юнит-экономику, ни качество.
- Безопасность: здесь мы прячем шифрование персональных данных, аутентификацию и проверку входного промпта на prompt injection.
- Кеширование: сохраняем популярные ответы, чтобы не гонять модели вхолостую.
- Контролируемая деградация: GPU неизбежно выходят из строя, а резервировать железо ×2 — удел AI-мажоров. Шлюз должен уметь перехватывать ошибки отвалившегося сервера и бесшовно переводить запрос на модель поменьше (или в код, или в модель в облаке). Пусть агент временно деградирует, но сама система продолжает решать задачу бизнеса (с контролируемо меньшим качеством).
Как делать инференс на всю компанию
Выжимать максимум из своих LLM — это отдельное искусство. Алгоритмы батчинга, квантизации, кеширования непрерывно обновляются в разных фреймворках (в статье, например, коллеги перечислили все 100500 примочек для инференса).
Эти методы не универсальны и сильно зависят от задачи. У вас должна быть выделенная ML-инфра команда, которая будет разбираться во всех нюансах инференса LLM. Их прямой KPI — удешевлять и ускорять генерацию токенов для разных продуктов компании. Чем больше потребление LLM в вашей компании, тем мощнее будет ROI этой команды.
В зависимости от того, как ваши продукты потребляют мощности, выбирается архитектура инференса.
1) Единый LLM-сервис на всю компанию. Одна команда развернула сервис с LLM. Все продукты ходят в эту одну общую «розетку».
- Плюсы: эффективная утилизация железа и проще сделать надёжную и стабильную архитектуру (она ведь всего одна).
- Минусы: больно кастомизировать инференс под специфические хотелки конкретных бизнес-юнитов. И нельзя разворачивать дообученные модели, разве что через LoRA, как мы обсуждали.
- Вердикт: всегда начинайте с этого. Идеально для старта и для продуктов с низкой или средней частотой запросов.
2) Выделенный LLM-инференс под продукт. Продукт физически забирает сервера с картами и разворачивает инференс сугубо под себя.
- Плюсы: можно тонко настроить инференс под конкретного потребителя и выжать максимум скорости.
- Минусы: если дать эту свободу всем подряд, вы получите зоопарк из сотни инференсов, где на каждом дорогущем сервере H100 будет обрабатываться по одному запросу в час.
- Вердикт: делать только для гигантских потребителей и строго после первого варианта. Ещё нужно создавать AI-полицию, которая ходит и проверяет, что этот большой продукт реально использует все карты, и отнимает их, если что.
Контекстное окно
Контекстное окно — это оперативная память агента. Именно тот текст (промпт), который подаётся в LLM, чтобы модель решила, что делать дальше. Внутри может быть всё что угодно: системный промпт, история работы агента, описание доступных инструментов и возможных действий.
Главный секрет надёжного агента можно сформулировать одной фразой: перед каждым новым действием в контекстном окне должна быть ровно та информация, которая нужна именно сейчас. Проблема в том, что мы заранее не знаем, что именно агенту понадобится на каждом конкретном шаге.
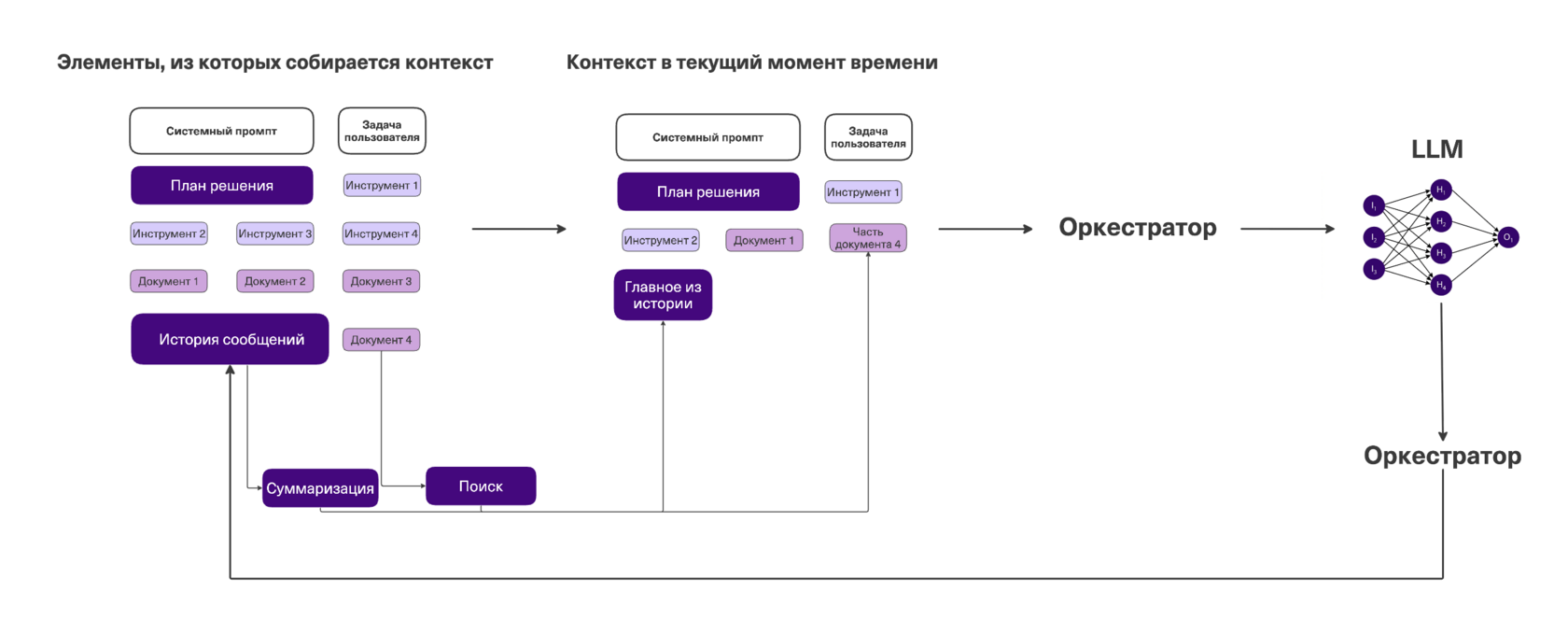
Самый очевидный дизайн контекстного окна — подавать вообще всё: полную историю, все инструменты, все возможные действия. Но это ловушка: чем длиннее контекст, тем хуже работает модель. Она начинает путаться, терять нить и галлюцинировать. Мусор в контексте — прямой путь к ненадёжному агенту.
Поэтому на практике используют специальные методы управления контекстом — context engineering. Их три, и они хорошо комбинируются друг с другом.
Хранение данных во внешних файлах
Не всю информацию нужно держать в контексте прямо сейчас. Объёмные данные можно вынести во внешний файл, а в контексте оставить только его идентификатор. Когда агенту понадобится эта информация — он сам загрузит файл или найдёт в нём нужное, например с помощью RAG.
Сжатие контекста
Часть накопленной информации можно сжать без потери смысла. Два способа:
- Правилами — результат инструмента, вызванного десять шагов назад, скорее всего уже не нужен. Убираем или сворачиваем.
- С помощью LLM — модель сканирует контекст, оценивает, что вряд ли пригодится дальше, и суммаризует это.
Изоляция контекста (мультиагентность)
Если задача явно делится на независимые части — каждую решаем в отдельном изолированном контексте. У каждого субагента своя конкретная задача и только та информация, которая нужна именно для неё. Никакого общего мусора — только то, что нужно.
Эти три метода не взаимоисключают друг друга. Хороший агент использует все три одновременно: выносит лишнее во внешние файлы, сжимает то, что осталось, и изолирует независимые задачи в отдельные контексты.
Безопасность
Безопасность в AI-агентах стоит острее, чем в обычных LLM — и причина одна: инструменты. Когда модель может читать файлы, писать в базы данных и вызывать внешние API, цена ошибки или взлома резко возрастает. Агент перестаёт быть просто чат-ботом — он становится актором с реальными последствиями.
Направления атак
Полный список рисков GenAI описан в стандарте OWASP (10 категорий). Здесь разберём самые критичные векторы атак и методы защиты от них.
1. Prompt injection. Злоумышленник подбирает специальный промпт, который заставляет модель нарушить инструкцию: выдать чужие данные, вызвать опасный инструмент или обойти ограничения. Чем мощнее инструменты агента — тем страшнее последствия. Агент с доступом ко всем базам данных и правом исполнять SQL-запросы — это уже серьёзная мишень.
2. Инъекция через данные. То же самое, но инъекция спрятана не в запросе пользователя, а в данных, которые агент читает в процессе работы. Например, в договоре, который агент анализирует, или в письме, которое он обрабатывает. Агент сам подгружает атаку себе в контекст.
3. Атака на внешние компоненты. Агент — это не только LLM. RAG, инструменты, базы знаний — всё это внешние системы со своими IT-уязвимостями. Взлом любого из компонентов может привести к утечке данных или компрометации всей системы.
4. Перегрузка системы (DoS). Клиент намеренно генерирует запросы, которые делают сервис слишком дорогим или медленным: огромное количество промптов подряд, аномально длинные запросы или специально сконструированные промпты, вызывающие массовый вызов инструментов. Цель — положить систему или разорить её владельца.
Методы защиты
1. Минимум инструментов. Большинство рисков идут от инструментов. Агент должен иметь доступ только к тем, которые необходимы именно для его задачи — не больше. Если используете мощные инструменты вроде исполнения кода, запускайте их в изолированной среде: без доступа к интернету, с ограниченными правами на файловую систему.
2. Контроль доступов. Агент, запущенный от имени конкретного клиента, должен видеть только данные этого клиента. Никакой инструмент не должен иметь возможность выгрузить информацию о других пользователях — это должно быть исключено на уровне архитектуры, а не промпта.
3. Детектирование инъекций отдельной моделью. Любой текст, поступающий в оркестратор, фильтруется специальной моделью, которая ищет инъекции и аномальное поведение. Модель можно специально дообучить на эту задачу или использовать как отдельный промпт к LLM. Если она что-то находит — исполнение блокируется до ручной проверки.
4. Маскирование персональных данных. Любые персональные данные в системе сначала выявляются специальными моделями, а затем маскируются или шифруются — до того, как попасть в контекст агента. Данные не должны утекать ни в логи, ни в промпты, ни во внешние API.
5. Лимиты на пользователя. Персональные ограничения на число токенов, количество последовательных вызовов и действий агента. Это базовая защита от перегрузки системы и неконтролируемых расходов.
Observability
LLM не славятся надёжностью. Галлюцинации в опросах — топ-1 барьер для внедрения их в бизнес. Ещё мы дали LLM кучу инструментов, разрешили ей планировать, добавили мультиагентность. Можно ли этот коктейль спроектировать так, чтобы всё это работало без сбоев? Нет. Обязательно что-то сломается. Но что мы должны спроектировать — так это механизмы быстрого анализа того, где и что сломалось.
Что такое observability
В обычной разработке всё прозрачно: код — источник правды. При любой ошибке можно разобраться, что пошло не так.
В AI-разработке код ничего не объяснит. Источник правды — только история: какие были входные данные и какие действия совершила модель. Набор методов для эффективного анализа этой истории и есть observability:
1. Сбор трейсов. Каждый новый запуск агента получает уникальный идентификатор, к которому привязываются все действия агента в рамках этого запуска. В итоге получается цепочка действий, которая называется трейс. Его дальше и анализируют.
2. Логирование. Все инструменты должны логировать входные данные, промежуточные состояния, ошибки и финальный ответ. Тогда инструменты в трейсе можно отдебажить.
3. Метрики качества (подробнее тут). В рамках одного трейса нужно обязательно оценить финальный ответ агента и, желательно, все его промежуточные действия. Разметить всё это вручную нереально, чаще используется LLM-as-a-judge (гайд по теме).
4. Дашборды. Помимо метрик качества, там должны быть технические метрики: скорость ответа, среднее число токенов и т.д.
Самые известные observability-библиотеки — это Langfuse и Arize Phoenix.
Как это всё работает вместе
- Вы мониторите состояние агентов на дашборде по техническим метрикам и метрикам качества.
- Если произошло падение метрик, выбираете трейсы, где аномально плохое качество, и дебажите: в какой момент времени и что именно сломалось.
- Во время дебага смотрите на прокси-метрики действий агента (через LLM-as-a-judge), проверяете все инструменты. Благо для этого мы заранее настроили логирование.
Без этого пайплайна разбор любой ошибки агента будет занимать вечность. И ваш проект так и останется на слайдах пилоте.
Чёрные технологичные ящики — это прикольно на презентации. Для инвесторов и начальников. Об этом прикольно рассказывать коллегам и друзьям. Но их очень не прикольно масштабировать и держать в продакшене. Любая поломка чёрного ящика — всю ночь будете разбирать причину. Лучше сделайте эти ящики прозрачными и спите спокойно.
Заключение
Мы разобрали анатомию AI-агента до винтика. Оркестратор, LLM, инструменты, контекстное окно, внешняя память, безопасность, observability — семь блоков, каждый со своей логикой и своими подводными камнями.
Но главное не в деталях каждого элемента. Главное в том, что агенты перестают быть магией, как только вы понимаете, из чего они сделаны. Магия — это когда непонятно, почему что-то работает или ломается. Инженерия — это когда вы знаете, в каком блоке искать проблему и как её чинить.
Именно к этому мы и шли с самого начала. Вот ваши детали. Теперь вы знаете, что они делают, как соединяются и где у каждой из них слабое место.
Честное предупреждение: это всё равно сложно. Агенты — не тот инструмент, который работает из коробки. Они галлюцинируют, застревают в циклах, ломаются в самый неподходящий момент. Но эта сложность теперь управляемая — у вас есть система, а не набор случайных экспериментов. А когда есть чёткая система, успех становится уже делом времени.
Если остались вопросы по построению AI-агентов в вашей конкретной задаче — напишите мне в Telegram, разберём вашу ситуацию.