Оценка качества — ключ к фреймворку успешного LLM-проекта. Если вы не овладеете этим навыком, любые ваши успехи, если они и будут, окажутся только случайной удачей. Почему?
LLM — это всегда проекты с высочайшей неопределённостью, а метрики нужны на каждом этапе проекта (подробнее про этапы — в прошлой статье). Мы обязаны быстро проверять, всё ли идёт хорошо. Сделали прототип — проверили качество. Не устраивает — пробуем что-то другое. Разработали финальную модель — проверили, что качество не упало относительно прототипа. Чем надёжнее и быстрее мы умеем мерить качество, тем увереннее и точнее будут наши шаги по этой туманной дороге.
Сегодня выведем пошаговый план создания метрик для LLM, обсудим, какими двумя главными свойствами метрика должна обладать, а в конце статьи вас ждёт финальная схема.
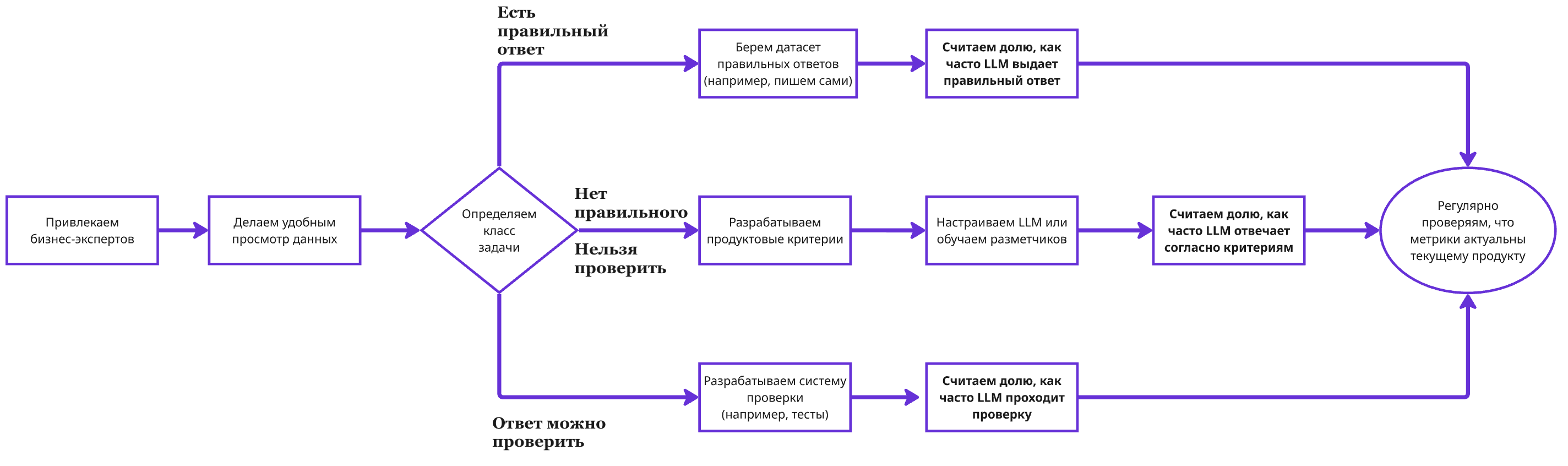
Шаг 1. Привлеките бизнес-экспертов
95% всех команд допускают одинаковую организационную ошибку, и сразу задача внедрения LLM становится неразрешимой: изолируют команду инженеров от бизнес-экспертов. На бумаге всё красиво: бизнес делает заказ на искусственный интеллект, головастые инженеры запираются в комнате и начинают этот интеллект воспроизводить. Главная проблема этого подхода: инженеры точно не знают, что им надо воспроизвести.
Хорошо, если они знают, что они не знают. Чаще всего они не знают и этого. И инженеры начинают придумывать свои собственные метрики качества, которые удобны и понятны только им самим. Запомните крепко два главных свойства хороших метрик качества: они отражают реальные проблемы бизнеса и они наглядны (все понимают, что считает эта метрика). И то, и другое невозможно соблюсти, если сидеть в башне из слоновой кости. Метрики рождаются только из практики реальных проблем реального продукта.
Например, мы делаем чат-бота поддержки для онлайн-магазина. Нужно аккуратно выписать важные проблемы, с которыми может столкнуться пользователь чат-бота:
- ответ никак не решает проблему пользователя
- ответ может казаться правильным, но в реальности ошибочен (более страшно, чем предыдущее)
- ответ оскорбляет пользователя (ещё более страшно)
Очевидно, что выписать такой список может только человек, который точно знает, что должен делать этот самый интеллект.

Шаг 2. Сделайте просмотр данных лёгким и удобным
Любая метрика рождается из реальных проблем реального продукта. Единственный правильный путь: брать данные и смотреть, какие проблемы у пользователей возникают (всё в соответствии с подходом из бережливого производства — гэмба).
Важно, чтобы каждому члену команды хотелось заглянуть в эти самые данные. Чтобы человеку не нужно было смотреть на 20 разных колонок непонятного формата, до которых нужно докопаться в 30 кликов мыши. Сделайте агрегацию данных, которые нужны для понимания ситуации: контекст диалога с LLM, текущий вопрос, ответ модели, важные внешние факторы (например, время, когда задали вопрос). И дальше настройте удобный просмотрщик данных (data viewer).
Человек с одного взгляда на интерфейс просмотрщика должен легко разобраться, что произошло в конкретном случае. Чтобы сделать хорошие метрики качества, смотреть придётся много. Для разных задач нужны разные просмотрщики данных. Популярные варианты:
- Google-таблицы. Самый быстрый и дешёвый способ для разметки данных. Всем понятный, всегда под рукой, легко проводить аналитику после разметки. Есть два больших недостатка. Не очень удобно отображать длинные цепочки данных (например, диалоги из 20 реплик). Не подходит, если у вас массовая разметка из десятка человек: есть риск что-то поломать в совместном редактировании.
- Label Studio. Опенсорс-продукт для разметки разных AI-задач, не только LLM. Это уже полноценный инструмент конкретно под задачу разметки. Есть все технические примочки, чтобы запускать массовые разметки. Но нужно устанавливать и всех учить пользоваться.
- Langfuse. Опенсорс-продукт конкретно для работы с LLM и агентами. Очень удобный для дебага агентов, имеет тонну функционала для просмотра текущего состояния агента, его действий и следующих состояний. Довольно тяжёлый в освоении, но очень функциональный.
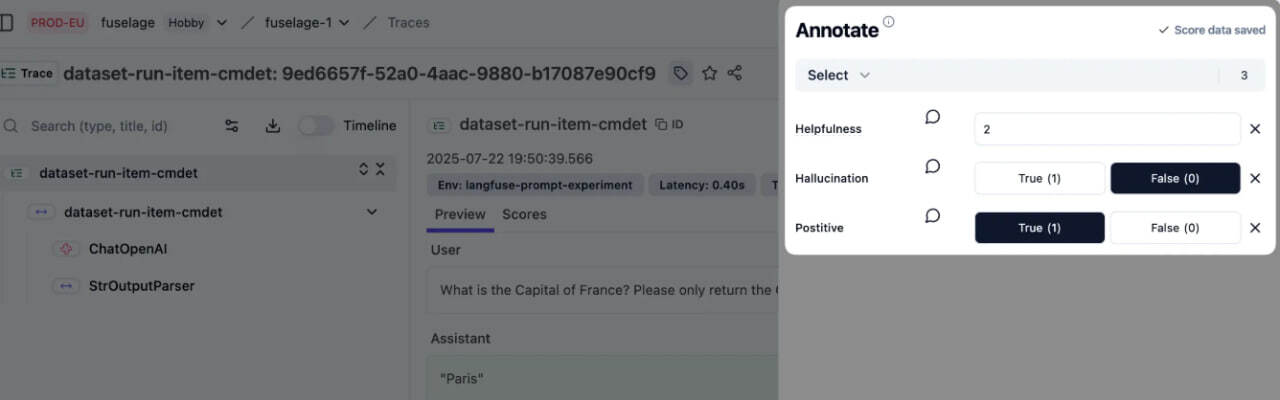
Шаг 3. Выберите метрику качества
Теперь время с бизнес-экспертом разобраться, какую метрику мы будем размечать. Не забываем про два главных свойства: отражает реальную проблему и наглядность.
В LLM есть 3 разных класса задач. В них по-разному нужно делать метрики качества.
1) Задачи, в которых есть точный ответ. Самый простой класс задач. Все метрики — это сравнение ответа модели с правильным ответом. Например, классификация, где вы сравниваете с правильным классом. Сравнивать можно не обязательно точным совпадением. Можно, например, текстовыми метриками (BLEU, WER) или отдельной моделью, например, BERT (bert_score). Чтобы метрика была наглядной, здесь лучше всего подходит «доля случаев, когда LLM выдала правильный ответ». Правильный ответ или нет можно определить по порогу BLEU, bert_score и т.д. Порог настроить на глаз на небольшом отдельном датасете. Главное — найти правильные ответы. В крайнем случае несколько сотен штук можно написать самим.
2) Задачи, в которых ответ можно проверить. Здесь тоже всё просто. Берём и проверяем. Например, если LLM генерит код, его можно прогнать на тестах. Или LLM генерирует доказательство теоремы, которое можно формально проверить. Чтобы метрика была наглядной, проще всего считать «доля случаев, когда LLM правильно решила задачу». Часто с первого раза LLM решает плохо, поэтому дают LLM много попыток: «доля случаев, когда LLM правильно решила задачу с первых k попыток» (Pass@k). Здесь главное — настроить систему проверки. Например, написать множество тестов, на которых проверять сгенерированный LLM код.
3) Задачи, в которых правильный ответ непонятно какой. С этим обычно самые трудности. И обычно здесь лежит большинство интересных LLM-задач. Делаем RAG-ассистента. Ответить можно миллионом способов, верифицировать ответ нельзя. Тогда нам нужны продуктовые критерии — «а что такое хороший ответ». Ответ LLM в нашем продукте должен быть релевантный, достоверный, актуальный… Для наглядности каждый критерий переводим в бинарный: «доля случаев, когда LLM ответила релевантно», «доля случаев, когда LLM ответила достоверно»… Дальше как-то агрегируем, например, «доля случаев, когда LLM ответила и релевантно, и достоверно…».
Далее следующие 3 шага написаны в первую очередь под третий класс, так как он наиболее трудный на практике. Но эти же идеи можно применять и в других классах.
Шаг 4. Выпишите критерии оценивания
У нас есть бизнес-эксперты, мы вместе с ними выбрали метрики, настроили удобный просмотрщик данных. Как нам теперь посчитать метрику? Если нет готовых ответов или нет возможности проверить ответ, нам нужно явно выписать продуктовые критерии: «какой ответ нам нравится, а какой нет». Часто этот выписанный набор критериев называют «инструкцией разметки».
Бизнес-эксперт не может просто запереться в комнате и их написать. Получится текст, оторванный от практики. Критерии можно только выстрадать. Выписать один раз, объяснить другим членам команды (другим бизнес-экспертам, AI-инженерам, менеджерам, аналитикам) и дальше всем вместе разметить.
В теории сразу всем критерии понятны, всей команде нравятся. Но на практике, когда пытаешься их применять к реальным данным, всё ломается. Например, плохие ответы получают хороший вердикт, а хорошие ответы — плохой. Или вообще наши критерии непонятно как применить. Это можно понять только в процессе разметки данных.
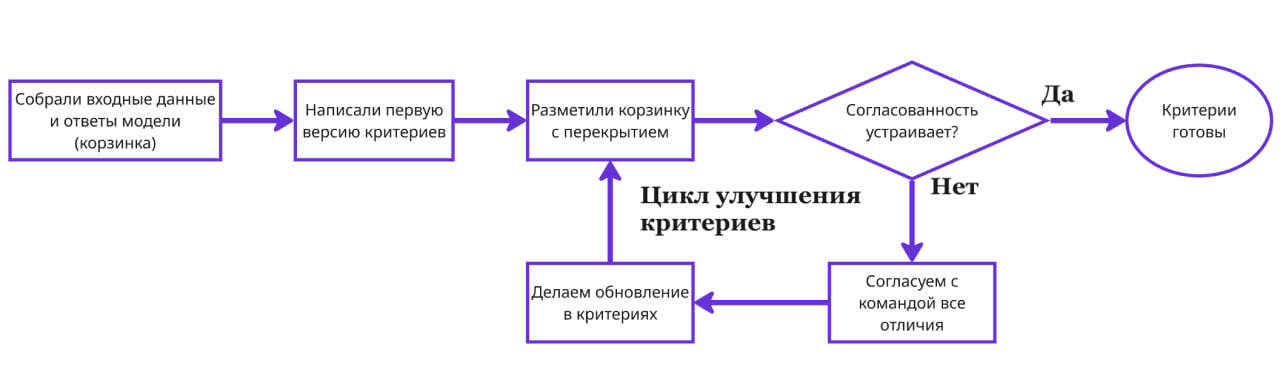
Мы берём небольшой набор данных (так называемую «корзинку» — это набор входных данных и ответов модели). Например, 100 примеров. И размечаем нашей командой эту сотню с перекрытием. С перекрытием — значит, что один и тот же пример вслепую размечают несколько человек (например, двое).
После разметки 100 примеров все случаи расхождения обсуждаются командой. Почему одному человеку этот ответ релевантен, а другой считает, что нет? Кто-то отметил, что это галлюцинации, а второй не согласился? Давайте встречаться и обсуждать. Затем результаты обсуждения заносить в инструкцию. И так пока мы не добьёмся нужной согласованности внутри команды. Субъективность в разметке нужно высушить до минимума.
Шаг 5. Решите, кто будет размечать
После того как мы внутри сошлись по критериям, можем думать про масштабирование разметки. Чтобы размечал кто-то, кроме нас. Это могут быть либо другие люди, либо LLM.
1) Разметка людьми. Используется для сложных метрик, которые текущие LLM не способны осознать. Это задачи, в которых нужна очень глубокая доменная экспертиза. Например, оценить достоверность консультации AI-юриста сможет только человек с юридической практикой, у которого под рукой нормативные документы. Но определить, была ли консультация токсичной, можно попросить LLM.
2) Разметка LLM (LLM-as-a-judge). Здесь ответы нашей LLM мы оцениваем «LLM-оценщиком». Почему мы можем доверить одной LLM проверять решение другой? Потому что проверить решение часто проще, чем создать решение с нуля. По-человечески это очень понятно — критиковать чужую работу всегда легче. Главные преимущества LLM-as-a-judge:
- Быстро настроить. Сделать LLM-разметчика сильно быстрее, чем обучить десятки людей следовать вашим критериям.
- Быстро размечает. Может за сутки оценить объёмы данных, которые люди будут размечать много лет.
- Дёшево. Стоимость генерации токенов обычно дешевле зарплаты разметчика. Но главное — для LLM-as-a-judge не нужна операционная работа. Чтобы надёжно работала разметка людьми, нужно потратить много сил: писать материалы, отвечать на вопросы, проводить тесты, экзамены. Проверять в процессе разметки, что они всё не забыли и не жульничают. Это требует отдельного штата специалистов. С LLM проще — настроил промпт и работает. Только иногда проверять, что не сломалось.

Шаг 6. Настройте разметку метрики
Теперь нам нужно научить разметчиков или LLM-разметчика работать по нашим критериям.
Разметка людьми
Настроить процесс разметки людьми — сложная операционная задача. Нужно научить множество людей одинаково с вами понимать критерии качества и размечать в соответствии с ними. Помимо этого обучения, нужно контролировать их работу, думать о найме новых сотрудников, системах мотивации и так далее.
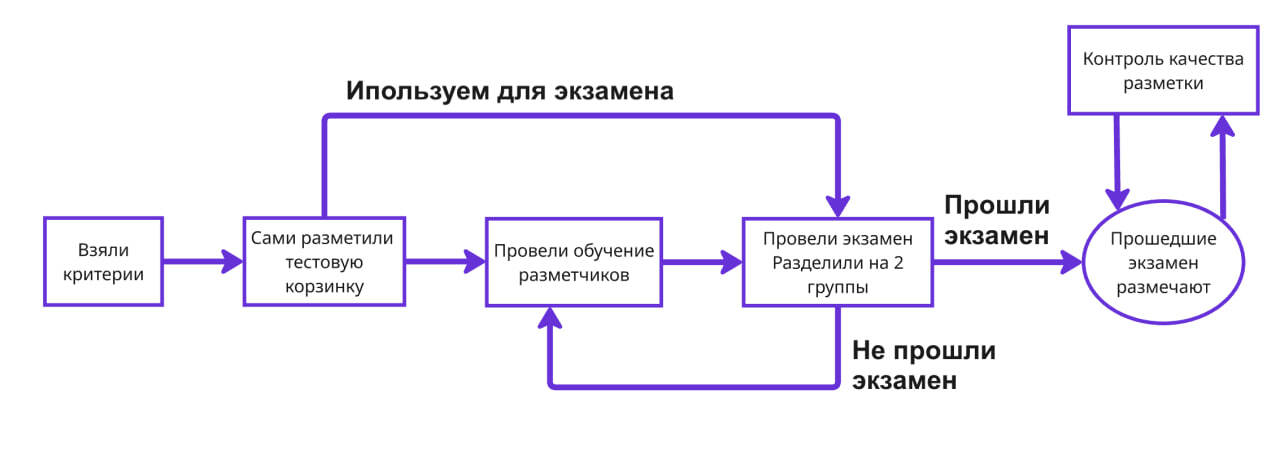
Большую часть работы по управлению командой разметчиков могут брать на себя готовые платформы, такие как Yandex Crowd Solutions или Amazon Mechanical Turk. Вам нужно будет только написать принципы разметки, а все инструменты работы с людьми уже есть на платформе. Главных инструмента всего 3:
- Обучение. Детальное описание критериев, видеоматериалы, примеры заданий. Всё, что поможет разметчику разобраться, что от него требуется. Обязательно стоит делать встречи, где разметчик может задать любые вопросы по критериям.
- Экзамен. Проверяем разметчиков на примерах, которые мы сами правильно разметили (мы же до этого долго сами согласовывались, так?). Всех, кто прошёл экзамен, допускаем дальше, остальных можно отправить на пересдачу.
- Контроль качества. Регулярно стоит проверять разметчиков на примерах, в которых нам известны правильные ответы. Ответы проставили или мы сами, или самые доверенные разметчики. Так можно находить халтурщиков и поощрять тех, кто качественно размечает.
Как видите, работа не самая простая. Поэтому, если сложность разметки позволяет, разумно попробовать LLM-as-a-judge.
Разметка LLM
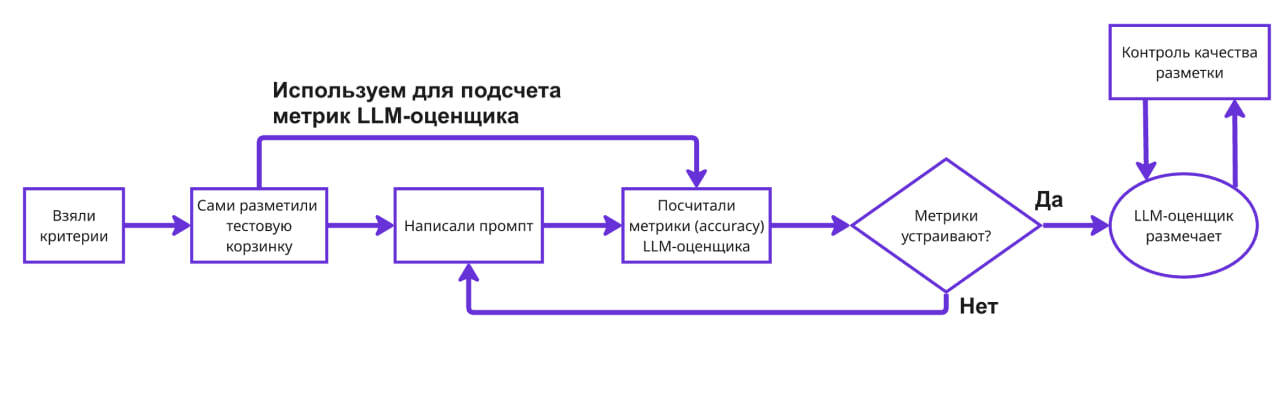
Здесь вместо обучения людей мы настраиваем LLM-разметчика. Как правило, настраивать модели намного быстрее. По сути, это отдельный мини-LLM-проект внутри нашего исходного проекта.
Настраивать LLM можно всеми 5 доступными способами из прошлой статьи: промптинг, добавление RAG, дообучение, инструменты или агентность. На практике для LLM-as-a-judge чаще всего используют обычный промптинг. Мы улучшаем промпт к LLM-разметчику, пока качество на тестовой корзине не станет нас устраивать.
Качество LLM-разметчика считать просто, так как это задача 1-го класса (задачи, в которых есть точный ответ). Мы уже сделали наглядную бинарную метрику, например, «релевантный ли ответ LLM». Далее сами размечаем релевантность ответов на небольшой корзинке, а затем сравниваем, что сказал на этих ответах LLM-as-a-judge. Сравниваем через метрику бинарной классификации, например, accuracy (процент правильно классифицированных ответов).
После этого всё равно стоит регулярно проверять качество разметки, так как может поменяться поток примеров в оригинальную LLM, и промпт оценщика придётся чуть поменять.
Шаг 7. Регулярно проверяйте и улучшайте метрику
Метрику качества не получится сделать один раз на всю жизнь продукта. Помните 2 главных свойства метрики? Они наглядны и отражают реальные проблемы.
Продукт меняется, люди задают другие вопросы, возникает новый функционал. Оценка качества LLM должна меняться вместе с продуктом. Мы собираем новую эталонную корзину, в которой только свежие данные, и проверяем, что текущие метрики хорошо на ней работают. Если плохо, разбираемся, что сломалось. Если критерии устарели — идём в Шаг 4. Если размечать стали хуже — в Шаг 6.
Итоговая схема
Вспомним всё, что мы изучили в статье:
- Первым делом привлекаем бизнес-экспертов. Без них говорить о качестве бессмысленно.
- Делаем удобным просмотр данных, чтобы всей команде было легко в них разобраться. Именно команда настраивает метрику — она должна точно понимать, что размечает.
- Выбираем метрику качества. Метрика зависит от класса задачи. Если в задаче есть правильный ответ — нужно выписать его на тестовой корзине и с ним сравнивать ответ LLM. Если ответ LLM можно проверить — нужно сделать программу, которая проверяет.
- Если ничего нельзя — пишем продуктовые критерии, по которым можно будет оценивать ответ.
- Выбираем, кто будет размечать: разметчики или LLM (LLM-as-a-judge).
- Обучаем разметчиков нашим продуктовым критериям или настраиваем LLM-as-a-judge (например, через промпт).
- Регулярно сверяемся, остаётся ли наша метрика актуальной для текущего продукта, или её нужно чуть поменять.
Надеюсь, теперь у вас сложилась в единое целое методика оценки качества LLM, и вы сможете применить её в своих проектах. В метриках качества есть огромное число нюансов, которые невозможно описать в одной статье. Если остались вопросы, как конкретно в вашем случае строить метрики качества — напишите мне в Telegram, разберём вашу ситуацию.