Большинство проектов с AI-агентами навечно останутся милыми пилотами. Gartner прогнозирует, что уже к 2027-му году более 40 % проектов с ИИ-агентами закроются. Дело не в том, что модели недостаточно умны (LLM уже решают олимпиады по математике лучше многих людей). Просто у команды внедрения нет нужной экспертизы. Команда не понимает, в каких процессах возникает реальная ценность от агентов и как правильно вести разработку проекта.
Обе проблемы разберем в статье. В первой части мы обсудим, как выбирать процессы, где агент способен создать реальную ценность — и почему большинство промахиваются уже здесь. Во второй — как управлять разработкой агентских систем так, чтобы они не застревали в статусе вечного пилота, а доходили до продакшена и там уверенно держались.
ЧАСТЬ I. ВЫБОР ПРОЦЕССА ДЛЯ РЕАЛЬНОЙ АВТОМАТИЗАЦИИ
Проект сразу обречен, если агенту не дают принимать решений. Агент подсказывает, суммаризирует, пишет черновик, но не принимает решений и не выполняет действий сам. Так безопаснее: человек все перепроверит. Но именно здесь и теряется почти вся ценность. Польза агента определяется не качеством текста, а количеством решений и действий, которые он может взять на себя. Я так же в детстве помогал папе делать ремонт: подавал инструменты, держал что-нибудь рядом, создавал ощущение совместной работы. Но ремонт, конечно, делал папа. Не уверен, что люди так же радуются помощи агентам, как моей помощи радовался отец.
Вторая проблема выбора процесса — команда даёт агенту не тот класс задач. Агенты хорошо работают там, где решение — это точное следование конкретному протоколу: прочитал регламент, выполнил шаги, получил результат. Там, где не нужно экспертного суждения, накопленного годами практики и интуиции. Именно этот класс задач агенты берут уверенно — и именно здесь можно получить реальный эффект.
Угрозы обозначены. На старт. Поехали выбирать процесс.
1. Автономность, риск и эффект
Агенты поражают, что могут автономно выполнять огромное число действий. Но в большинстве внедрений человек проверяет каждое решение. Кажется, что это разумно — меньше автономности, меньше риска. Риск действительно падает. Но вместе с ним падает и весь эффект. Агент становится дорогим способом генерировать красивый текст, который, постоянно отвлекаясь от другой работы, пересматривает человек.
Настоящая ценность агента измеряется тем, сколько решений и действий он берёт на себя. Агент, который суммаризирует диалог с клиентом — это почти нулевая ценность. Агент, который сам читает диалог, принимает решение по регламенту, обновляет статус заявки в CRM и отправляет клиенту письмо — это уже реальная автоматизация. В такой автоматизации невероятно растет риск сломать процесс. Поэтому процессы нужно выбирать с умом.
Чем определяется автономность AI-агента
Многие путают уровень автономности с интерфейсом, через который человек взаимодействует с агентом. Возьмём разработку кода. Один и тот же интерфейс — копилот, разработчик дает агенту конкретную задачу через промпт. Копилот, который дописывает только одну следующую строчку в одном файле — низкая автономность. Но копилот, который под капотом обходит десятки файлов, анализирует архитектуру, выбирает структуры данных и потом еще пишет код целой библиотеки — это уже настоящая автоматизация.
Автономность агента определяется двумя вещами: выбором оркестратора и тем, какие инструменты ему доступны. Самый предсказуемый вариант — LLM-workflow: фиксированная цепочка шагов, прописанная разработчиком. Агент не решает, что делать дальше — он идёт по графу. Риск минимален, но и свобода ограничена числом веток в этом графе. На другом конце спектра — свободный автономный агент с доступом к браузеру, коду и внешним API. Он сам планирует, сам выбирает инструменты, сам решает когда остановиться. Мощно — и очень рискованно. Подробнее про варианты оркестрации можно посмотреть в моей статье.
Большинство реальных продакшен-систем живут где-то посередине: предсказуемый workflow, в узлах которого вызываются более автономные агенты для сложных подзадач.
От автономности зависят и эффект, и риск
В разработке агентов, как в инвестициях: за потенциальную выгоду мы платим риском. И обе величины зависят от автономности.
Агент с низкой автономностью — это низкий риск и низкий профит. Агент с доступом к CRM и правом отправлять письма клиентам может сделать в сто раз больше полезного, чем агент-суммаризатор. Но и навредить — тоже в сто раз больше.
Связку удобно представить двумя кривыми. Риск растёт экспоненциально: каждая капля автономности не только увеличивает шанс ошибки, но и добавляет новые требования к инфраструктуре — контроль доступов, защита от prompt injection, observability, отладка зацикливаний. Профит ведёт себя иначе. Сначала тоже растёт быстро: автономность открывает новые сценарии, которые в жёстком workflow невозможны. Но в какой-то момент он выходит на плато — модель упирается в потолок текущих технологий, начинает галлюцинировать и тупить от переизбытка инструментов. А дальше профит и вовсе разворачивается вниз: дополнительная автономность не помогает, а вредит, потому что система ломается чаще, чем создаёт ценность. Где-то между ростом и плато — точка оптимума, в которой и стоит держать систему.
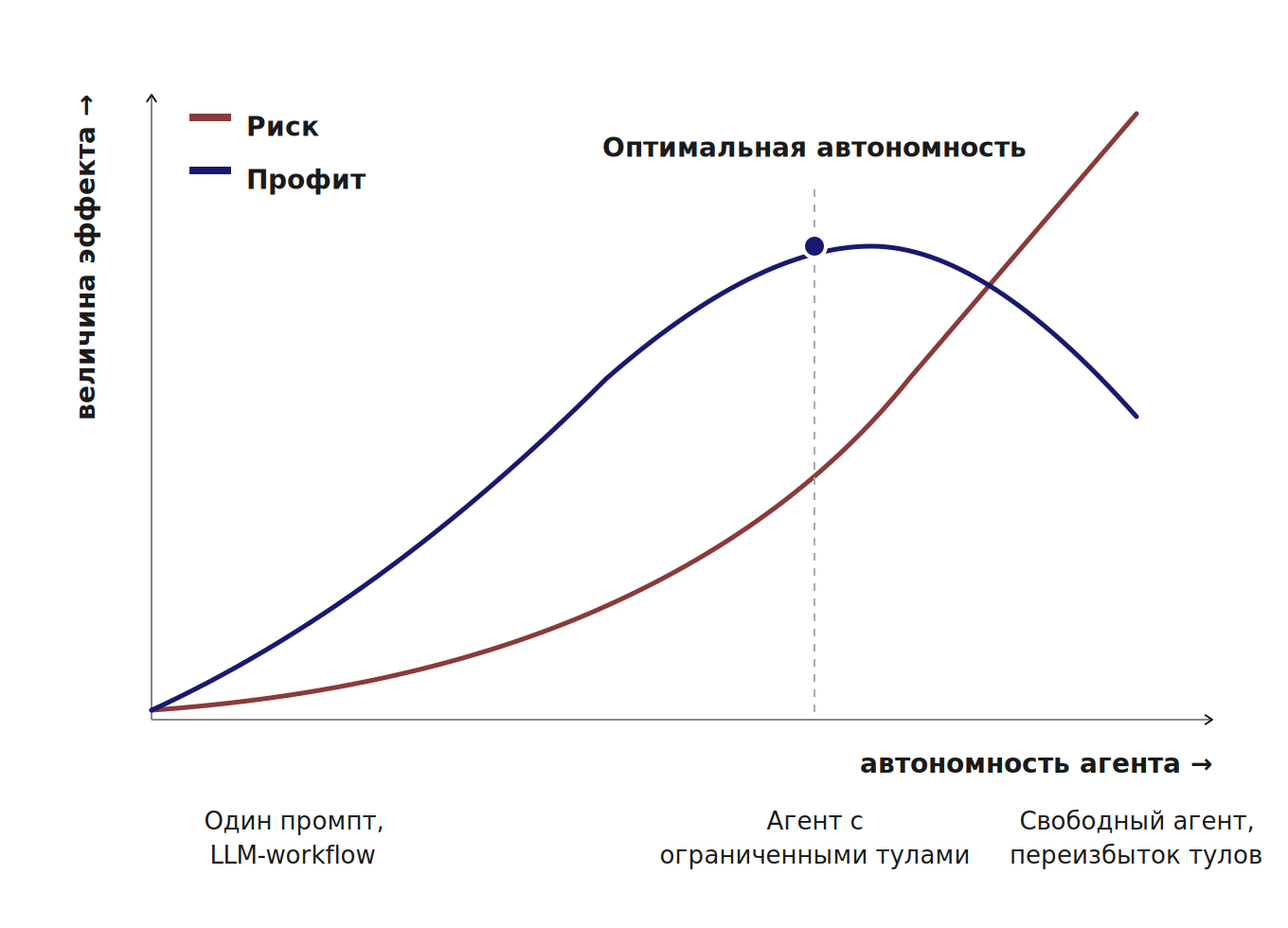
Толерантность к риску у всех разная. Стартап, которому нужна демка к следующему раунду, может позволить себе взять самого автономного агента и закрыть глаза на часть рисков. Цена ошибки невысокая, скорость важнее надёжности. Крупный банк, который автоматизирует процесс под надзором регулятора, живёт в другой реальности. Каждое решение агента потенциально аудируемо. Цена ошибки — штраф, репутация, регуляторные последствия. Здесь уровень автономности подбирается под то, что команда способна контролировать.
Толерантность к риску — один из главных критериев выбора процесса для агентизации. Именно она определяет, во сколько вам обойдётся разработка. Чем ниже толерантность — тем больше придётся вложить в контроль качества, мониторинг и инфраструктуру (подробнее в посте). Поэтому вам кажется, что стартапы самые технологичные, они используют самые мегатехнологии, которые недоступны неповоротливым корпорациям. Нет, технологии такие же, просто стартапам нечего терять.
2. Агенты: intelligence или judgment?
Даже если команда берет на себя риск и претендует на настоящую автоматизацию, сам процесс может не подходить под агента. Чтобы это объяснить, удобнее всего использовать разделение, которое недавно удачно сформулировали в Sequoia: любая работа состоит из двух типов задач — intelligence и judgment (я не смог никак нормально перевести на русский).
-
Intelligence — это задачи, где есть понятный процесс. Вот тебе подробная вводная, вот регламент, вот критерии хорошего результата — иди и делай. Решений в процессе принимается много, но они опираются на здравый смысл и инструкцию. Любой грамотный человек должен справиться.
-
Judgment — это экспертные суждения. Решения, которые опираются на интуицию, накопленную годами практики. Их невозможно описать в виде процесса. Невозможно стандартизировать. Невозможно положить в промпт фразой “представь, что ты программист с 20-летним опытом в C++” и получить результат уровня этого программиста.
Грань хорошо видно на программировании. Выбрать архитектуру отказоустойчивого высоконагруженного приложения — это чистый judgment. У человека либо есть опыт десятка таких систем и интуиция, как сделать сейчас, либо нет. Это нельзя описать правилом “при таких условиях всегда выбирай PostgreSQL”. А вот написать код по подробной инструкции от синьора — это уже intelligence. Решений много, но все они в рамках понятного протокола, который тебе описали.
Человеку — judgment, агенту — intelligence
Посмотрите, как опытные разработчики используют агентов в коде. Они не пишут в промпте “напиши мне приложение, как будто ты эксперт со 100 годами опыта который пил кофе со Страуструпом”. Они пишут детальную спеку: какая архитектура, какие модули, какие интерфейсы, какие тесты должны пройти. И только после этого отдают задачу агенту. Синьор взял на себя judgment — выбор архитектуры, оценку рисков, расстановку приоритетов. И свёл задачу агента к чистому intelligence: “вот спека, сделай ровно по ней”. Дальше синьор проверит результат — но проверит уже в рамках своей спеки, а не пытаясь оценить, “хороший ли это код вообще”.
Внутри intelligence-задачи агент принимает огромное количество микрорешений: как назвать переменную, какой функцией реализовать, как разбить на классы. Но все эти решения — внутри понятных рамок. Ровно поэтому всё работает.
И ровно поэтому ломается обратный сценарий — vibe coding, когда не-разработчик пытается писать продукт через агента. Пока задача элементарная, всё нормально. Как только начинается что-то сложное — агенту приходится самому делать judgment-выбор: какую архитектуру, какие компромиссы. Он его сделает — но не так, как сделал бы эксперт. И никто его не проверит.
Почему агенты работают только в intelligence
Первая причина — агентов делают через context engineering. 99% разработки агента — это про то, как в нужный момент положить в контекст модели нужную информацию. Регламент, документация, примеры, текущее состояние процесса. Если у вас intelligence-задача — вы знаете, что класть. Если judgment — вам просто нечего туда положить. Вы не можете записать в промпт двадцать лет опыта.
Вторая — метрики качества (как их готовить, я писал отдельную статью). Без них агент в продакшен не уедет. В intelligence-задаче у вас есть протокол, и вы можете оценить, насколько агент ему следует. Это даёт вам разметку, дашборды, способ ловить ошибки и улучшать систему. В judgment-задаче протокола нет — а значит, нет и способа сказать, хороший ответ или плохой. Любая попытка построить метрики превращается в спор экспертов, которые сами друг с другом не согласны.
3. Какие процессы подходят для AI-агентов
Теперь мы готовы выписать три критерия, по которым процесс должен проходить проверку.
1. Громадный, ну просто колоссальный эффект
Делать агентов — дорого. Очень-очень дорого, если вы не толерантны к риску. Особенно неприятно, что оценить разработку невероятно сложно заранее (об этом следующая глава). Поэтому не имеет никакого смысла ввязываться, если на кону не большой куш.
Агент создаёт ценность только тогда, когда берёт на себя значимый объём решений и действий, которые сейчас делает человек. Это первое и главное. В процессе должно быть достаточно много шагов, которые агент может закрыть сам: ходить в системы, собирать данные, принимать решения по регламенту, заполнять документы, отправлять сообщения.
У этого эффекта должен быть понятный KPI, к которому можно честно атрибутировать результат. Здесь полезно держать в голове три типа профита от автоматизации.
-
Уменьшение затрат. Самое очевидное: было десять операторов — стало пять. Для агентов это пока работает плохо, потому что 30% экономии на процессе обычно не окупает команду разработки и стоимость LLM. Исключения — суперчастотные процессы вроде поддержки и продаж.
-
Снижение числа ошибок. Особенно ценно в рисковых процессах, где одна ошибка стоит дорого: юридический иск, простой производства, штраф от регулятора. Здесь экономия считается через стоимость предотвращённой ошибки.
-
Создание новой ценности. Раньше клиент согласовывал страховой случай две недели — теперь за 15 минут. Раньше продакт-менеджер ждал отчёт от аналитика три дня — теперь получает за минуту. Здесь обычно самые большие деньги — но и самый сложный для подсчёта эффект.
Важная оговорка: не всегда профит надо жёстко переводить в деньги. Вы ускорили поддержку, и теперь пользователь решает вопрос за 15 секунд вместо пяти минут на телефоне. Это конкурентное преимущество. Но точно посчитать “сколько денег это принесло” — почти невозможно. Или агент-аналитик, который отвечает менеджерам на продуктовые вопросы (пример такого агента). Безумно полезно — все начинают принимать решения на данных. Как это посчитать в рублях? Никак прямо. И это нормально. Иногда даже в нашем капиталистическом мире выгодно быть визионером.
2. Есть ресурсы, чтобы выдержать риск
Каждый процесс имеет свою терпимость к ошибкам — и она должна быть совместима с тем, что текущие ресурсы способны обеспечить. На самом деле, деньги — это последнее, о чём вам стоит беспокоиться. Главное — команда с нужной экспертизой.
Есть процессы, где любая ошибка означает большой убыток: регуляторные документы, медицинские решения, финансовые операции под надзором. Здесь нужна тяжёлая инфраструктура контроля: разметка качества, человеческая проверка, отказоустойчивость, аудит каждого решения. Возможно — но дорого, долго и не всегда оправдано.
Заранее предсказать точно, сколько потребуется ресурсов нереально. Но на этапе выбора достаточно отсечь самые рискованные кейсы — те, где регулятор дышит в спину, или где вы прямо сейчас понимаете, что цена одной ошибки для бизнеса неприемлема.
3. Природа задачи: intelligence, а не judgment
Представьте агента как очень исполнительного сотрудника, которого только что наняли с улицы. Он не знает ничего: ни вашей компании, ни процессов, ни клиентов, ни внутренней терминологии. И вашу задачу он сделает ровно так, как вы её ему объяснили в этот момент.
Простой тест: сядьте и попробуйте написать регламент — что делать, куда ходить, как принимать решения, что считать хорошим результатом. Если получилось — у вас intelligence, агент справится. Если получилось плохо или вообще никак — либо в процессе бардак (фиксите бардак, не агента), либо это judgment (агент вам не поможет в принципе).
Итоговое правило
Эти три критерия можно свести к двум вопросам.
-
Профит, который процесс способен принести после агентизации, должен быть значимо больше, чем стоимость инфраструктуры контроля, нужной для удержания риска на приемлемом уровне. Значимо, потому что инфраструктуру вы заведомо неправильно оценили.
-
Этот процесс можно описать понятной инструкцией, понятной человеку, который случайно встретился вам на автобусной остановке.
Напоследок несколько примеров.
-
DoorDash — поддержка курьеров. DoorDash построили агентскую систему поддержки для курьеров. Я подробно разбирал их архитектуру. Эффект: генеративная система отвечает на тысячи обращений в день — счёт идёт на десятки миллионов долларов экономии в год. Природа задачи: есть верифицированная база регламентов — чистый intelligence. Риск: каждый ответ проверяется отдельной LLM на галлюцинации; если она сомневается — кейс уходит человеку.
-
Lemonade — автоматическое одобрение страховых выплат. Страховая Lemonade построила агента, который сам обрабатывает претензии. У клиента угнали велосипед — он подаёт заявление через приложение, и примерно в трети случаев деньги приходят на счёт за несколько секунд. Эффект: создание новой ценности. Не “сэкономили на операторах”, а другой клиентский опыт. Природа задачи: регламент страховых выплат кодифицирован — intelligence. Риск: автоматизируется только треть случаев, самых понятных. Подозрительное и сложное уходит человеку.
-
Stripe Smart Disputes — автоматическая защита от возвратов. Когда покупатель говорит банку “я этого не покупал, верните деньги”, банк списывает деньги с продавца. Чтобы их отстоять, нужно быстро собрать доказательства и отправить банку. Долго и муторно — многие продавцы просто забивают. Агент Stripe делает это сам: собирает данные о транзакции, формирует пакет, отправляет до дедлайна. Эффект: возвратов миллионы в год. Природа задачи: правила банковских сетей формализованы, данные есть — чистый intelligence. Риск: агент берёт только те кейсы, что подходят по чётким критериям. Сложное не трогает.
ЧАСТЬ II. ПРОЦЕСС РАЗРАБОТКИ AI-АГЕНТОВ
Главная сложность AI-разработки — её невероятно сложно прогнозировать. В классической IT всё относительно понятно: вы знаете, что Kafka выдержит вашу очередь. Вы прочитали это в спецификации, вы увидели код, вы точно знаете, что технология подходит. С AI так не работает. Ещё нет надежных практик в индустрии, десятилетий накопленного опыта. Может оказаться, что конкретно в вашей задаче самая модная автономная архитектура не справляется, а связка из двух простых компонентов решает проблему. У ваших ML-лидов может быть интуиция, но узнать наверняка заранее нельзя — только в процессе.
Отсюда два вывода. Первый — разработка должна быть гибкой и итеративной. Каждый процесс уникален, заранее зафиксировать архитектуру и стек на полгода вперёд нереально. Команда, которая пытается так работать, упирается в стену в первый же месяц — и либо сломает план, либо сломает проект. Второй — резко вырастает роль ML-руководителя. Это уже не просто менеджер функции, а человек, у которого больше всех инженерной интуиции. Именно он раньше всех замечает, что команда движется не туда, и быстро её разворачивает. Без сильного лида вы не сможете быть достаточно гибким и упретесь в решение, которое надо было поменять полгода назад.
Для сильного ML-лида и написаны следующие главы. Не стоит полностью повторять тот опыт, который был в классическом ML. Лучше давайте обсудим, как разрабатывать успешных AI-агентов.
4. Забудьте про обучение LLM
В классическом ML всё устроено по понятному циклу: поняли задачу, собрали данные, обучили модель, оценили качество. Не получилось — собрали ещё данных, переобучили. Многие в индустрию шли именно за этим — обучать модели интересно.
С AI-агентами этот рефлекс работает против вас. У вас на руках уже есть базовая LLM, на обучение которой ушли миллионы GPU-часов и весь интернет. Это не модель, которую вы строите с нуля под свою задачу — это огромная универсальная штука, которую нужно научить решать конкретно вашу. И дообучение — почти всегда плохой способ это сделать.
Почему дообучение не работает
Главное заблуждение: что дообучением можно добавить в модель знания. Не получится. Модель уже видела весь интернет на претрейне — ваши восемь часов файнтюна на H100 её картину мира не перевернут. Если модель не стала юристом на всех текстах человечества, на тысяче ваших примеров она тем более им не станет.
Хуже того, дообучение легко портит то, что уже работало. LLM проходят отдельную стадию alignment — длинную и дорогую настройку, которая учит модель отвечать на вопросы, не нести чушь и не выдавать системный промпт по первому запросу. Это часть гарантии, которую даёт провайдер. Когда вы меняете веса — гарантия слетает. Могут резко вырасти галлюцинации: если в файнтюн попали факты, которых не было в претрейне, модель оказывается в положении студента, выучившего билеты за ночь — вроде что-то знает, но при первом серьёзном вопросе уверенно врёт. Эту проблему хорошо описали коллеги из Google.
Когда дообучение всё-таки нужно
Дообучение может поправить форму ответа: когда промпт настолько раздулся, что модель в нём путается, часть инструкций можно зашить в веса. На практике до этого доходит редко и обычно только на маленьких моделях — большие справляются и так.
Бывают и серьёзные применения — например, обучить новые навыки рассуждения через RL. Но это R&D-задача с отдельной командой и большим бюджетом на эксперименты. Если вы читаете эту статью — вам, скорее всего, туда не надо.
Единственный кейс дообучения, который реально окупается на практике, — дистилляция. Это когда вы обучаете маленькую модель повторять ответы большой, чтобы радикально сэкономить на инференсе. Об этом — в следующей главе.
5. Инструкция по сборке AI-агентов
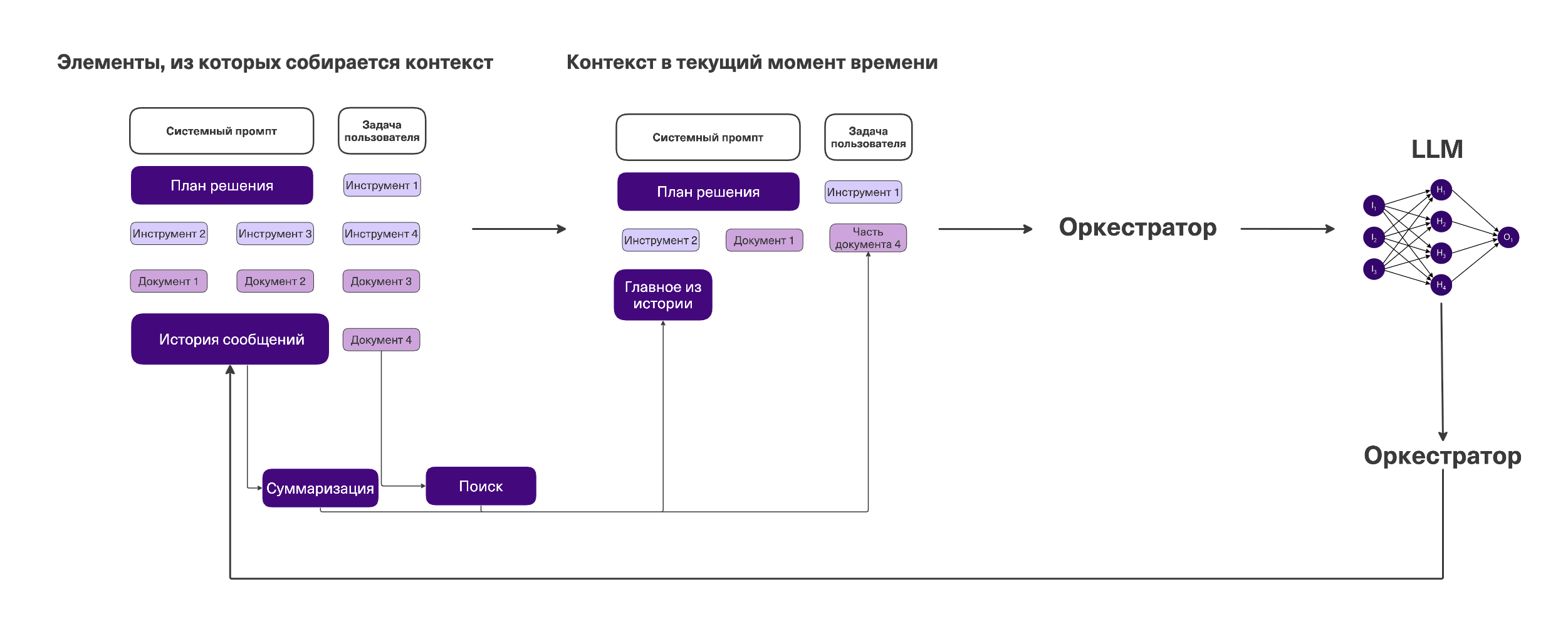
Хорошая новость: почти всё, что вы могли получить от дообучения, делается через работу с контекстом. Базовая модель уже умеет всё нужное — её нужно объяснить, что от нее требуется. Большая часть инженерных усилий уходит на то, чтобы в нужный момент в контекст модели попала ровно та информация, которая нужна для текущего шага. Это и есть работа с контекстом или по-западному context engineering.
Методы работы с контекстом
Базовых приёмов несколько.
-
Системный промпт с чёткой целью и инструкцией. Не “ты помощник, отвечай вежливо”, а конкретное описание задачи: что делать, какие правила, что считать хорошим результатом, в каких случаях останавливаться (как же хорошо, что наша задача intelligent).
-
Описание инструментов. Каждый тул должен иметь понятное название, описание входных и выходных параметров, примеры использования. Если описание сделано на отвали — агент будет либо вызывать инструмент не вовремя, либо передавать в него мусор.
-
Нормальный вывод инструментов — особенно ошибок. Когда тул упал, агент должен видеть, что именно сломалось, чтобы понять, как действовать дальше. Просто “Error” без деталей превращает агента в слепого.
-
Поиск по знаниям. Здесь обычно сразу хватаются за векторный поиск, но в большинстве случаев обычного полнотекстового поиска через grep вполне достаточно — он проще, дешевле и предсказуемее. Я сам люблю grep.
-
Сжатие контекста. При долгой работе контекст становится уже таким большим, что LLM начинает тупить и выбирать неправильные действия. После какого-то размера можно включить суммаризацию (тоже на LLM), которая сожмет информацию. Также можно просто переносить часть информации не в контекст, а в отдельные файлы. Например, вывод пока ненужных тулов отправлять туда. Потом прочтем другим тулом при необходимости.
Стадии разработки AI-агентов
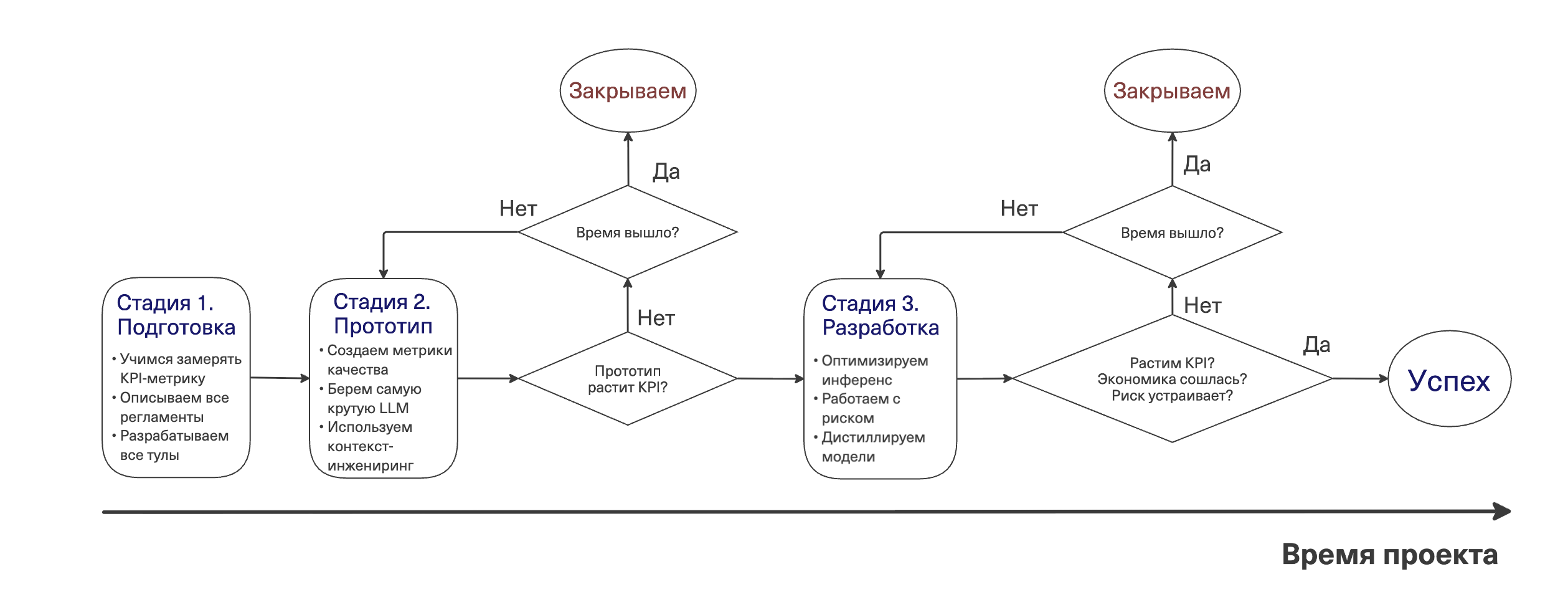
Не надо сразу бросаться разрабатывать все-все-все. Есть три стадии разработки, их нужно проходить последовательно.
-
Подготовка. До того как писать первую строчку кода агента, нужно три вещи. Первое — выписать все регламенты процесса. Второе — подготовить инструменты с нормальными описаниями: и те, что забирают контекст, и те, что выполняют действия. Третье — подготовить расчет KPI-метрики, по которой мы будем оценивать проект. Если вы настроены серьезно, можно подумать про AB-платформу и дизайн AB-экспериментов.
-
Прототипирование. На этой стадии главный риск — потратить месяцы на проект, который вообще не должен был существовать. Поэтому здесь запрещено думать про стоимость инференса, скорость и оптимизации. Берём самую дорогую и сильную API-модель на рынке, собираем архитектуру, проверяем гипотезу, что задачу реально сделать. Здесь нам уже потребуются быстрые итерации, для этого нужно уметь замерять качество. Каждое изменение прототипа проверяется метриками. Поменяли системный промпт — посчитали метрики, посмотрели результат. Добавили новый тул — прогнали эвалы. Подробная инструкция про настройку метрик — в моей отдельной статье. В итоге считаем KPI-метрику, которую определили на этапе 1. Если прототип не завелся — гипотеза не подтвердилась, проект честно закрывается. Не тратим время и деньги. Если справился — переходим дальше.
-
Разработка. Сигнал получили, гипотеза подтвердилась — теперь оптимизируем. Здесь стоит заняться оптимизацией инференса (подробнее в посте). Если все равно дорого — на сцену выходит дистилляция. Это когда вы берёте маленькую модель и обучаете её повторять ответы большой на ваших конкретных задачах. Маленькая модель теряет универсальность (на задачах вне вашего домена будет тупить), но вашу конкретную задачу решает на уровне большой и стоит на порядок дешевле. Здесь нужно сравнивать оптимизированную версию с тем, что было на прототипе. Как замечательно, что на прошлом этапе вы уже разработали метрики. На этой же стадии мы работаем с уменьшением рисков системы, чтобы можно было спать спокойно по ночам (подробнее про методы в следующей главе). Вопросы для успешного завершения проекта. Первый: все еще растим KPI (не сильно ли испортили прототип)? Второй: экономика сошлась? Третий: риск контролируем?
Все равно, на чем вы разрабатываете агентов
Что определяет результат: описание бизнес-процесса, нормальные инструменты с понятными описаниями, метрики качества, дешёвый и быстрый инференс. Уберите любой пункт — агент не полетит. А на чём вы это всё собираете — n8n, LangGraph, CrewAI, голый питон или что-то ещё — не имеет значения. Это разные обёртки разной приятности над одной и той же логикой “положи нужный текст в контекст и вызови LLM”.
Выбор фреймворка скорее определяется составом команды. Есть много людей, которые пишут на питоне и разбираются в разработке агентов — берёте “низкоуровневые” фреймворки вроде LangChain. Команда другая — выбираете то, что ей подходит. Фреймворк — не главное. Если понимаете, как работает, с любым разберётесь.
6. Как удерживать риск под контролем
В первой части мы договорились: ценность агента растёт вместе с его автономностью, а вместе с автономностью растёт и риск. Хорошая новость в том, что у вас intelligence-процесс и для него есть протокол. Именно он становится опорой всего контура контроля: по нему вы оцениваете действия агента, ловите отклонения и решаете, когда вмешиваться.
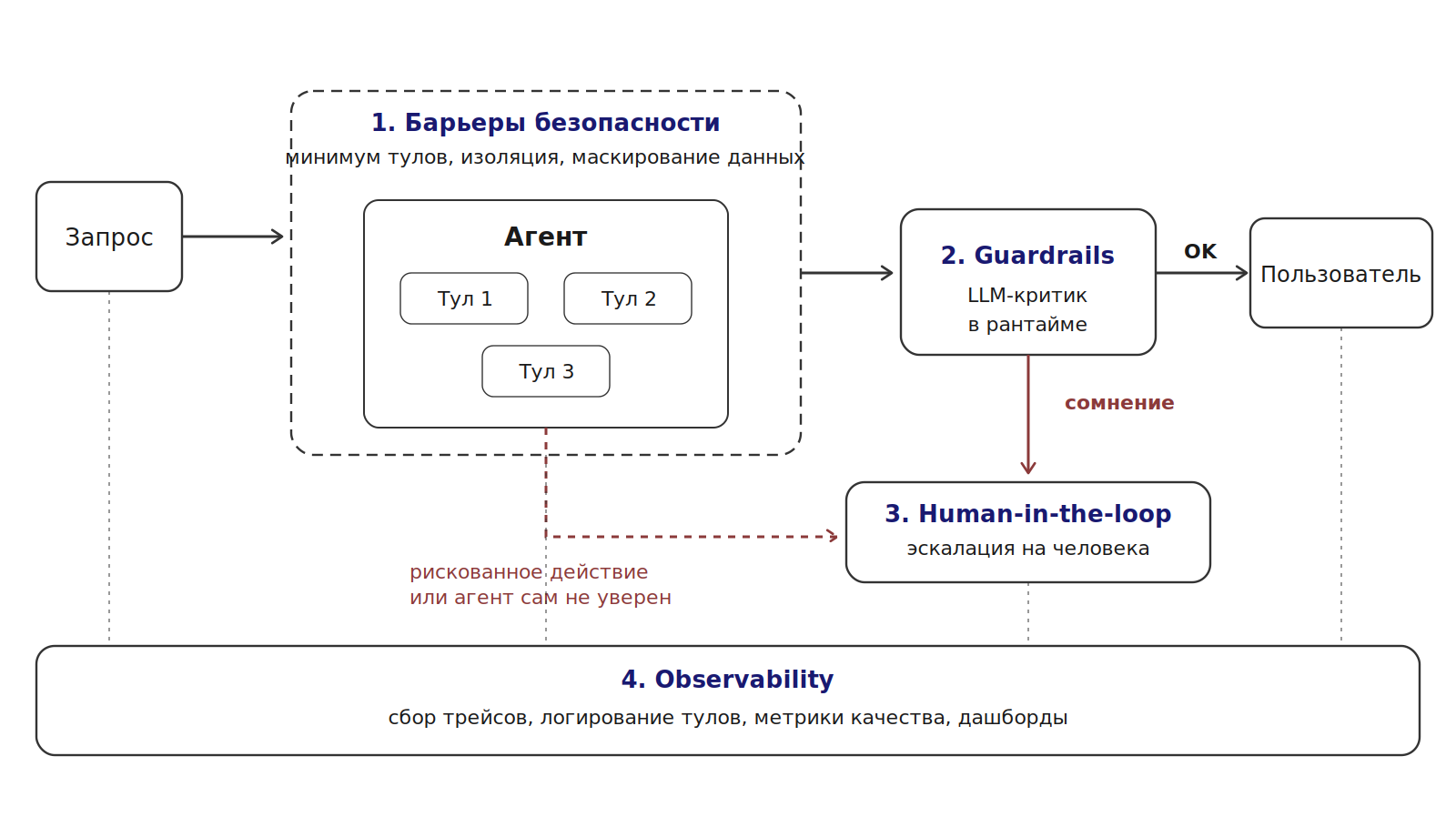
Дальше — четыре уровня контроля, которые работают вместе. Над ними стоит серьезно работать на третьем этапе, когда уже доказана ценность продукта.
1. Observability — прозрачность агента
LLM не славятся надёжностью. Спроектировать систему так, чтобы она не ломалась никогда, не получится. Что нужно спроектировать — это механизмы, которые позволят быстро понять, где именно сломалось.
В классической IT-разработке всё прозрачно: код — источник правды, по нему всегда можно восстановить, что произошло. В AI-разработке код ничего не объяснит. Источник правды — только история действий: какие были входные данные, в каком состоянии был агент, какие тулы он вызвал, что получил в ответ, что сгенерировала LLM. Набор методов для эффективного анализа этой истории и называется observability.
В минимальном виде нужны четыре компонента. Сбор трейсов — каждый запуск агента получает уникальный идентификатор, к которому привязываются все его действия. Логирование тулов — входы, выходы, ошибки, промежуточные состояния. Метрики качества — оценка финального ответа и промежуточных шагов. И дашборды — в реальном времени видеть, не просело ли качество, не выросло ли число ошибок. Часть из этого есть в опенсорсе, например в библиотеке Langfuse.
Без этого пайплайна разбор любой ошибки агента занимает вечность, и проект так и остаётся в статусе пилота. Чёрные ящики — это прикольно на презентации; в продакшене они превращаются в бессонные ночи (у меня такое было, повторять не рекомендую).
2. Guardrails — критик в рантайме
Observability помогает разбираться постфактум. Но часто этого мало — нужно ловить плохие ответы до того, как они доедут до пользователя. Для этого ставят guardrails: отдельную LLM-критика, которая в рантайме оценивает действия агента по тем же критериям, что вы используете для метрик качества. Например, ответ построен на найденных документах или выдуман из весов? Соответствует ли он регламенту? Корректен ли язык? Если что-то не так — ответ блокируется. Обычно такие модели обучают так, чтобы они предсказывали метрику качества. О, как удачно, что их мы разработали на прошлом этапе.
Хорошая иллюстрация — система поддержки в DoorDash, которую я подробно разбирал. У них guardrails стоят и до генерации ответа (проверяют, что найдена релевантная инструкция), и после (проверяют сам ответ на галлюцинации). Если на любом этапе модель сомневается — кейс не геройски обрабатывается агентом, а тихо передаётся живому оператору.
3. Барьеры безопасности
Обязательно надо строить барьеры на уровне системы.
-
Минимум инструментов. Большинство рисков идёт от инструментов. Агент должен иметь доступ только к тем тулам, которые нужны для его задачи. Мощные инструменты вроде исполнения кода запускаются в изолированной среде.
-
Контроль доступов. Агент, работающий от имени конкретного клиента, должен видеть только его данные. Никакой тул не должен в принципе уметь выгружать информацию о других пользователях — это исключается на уровне архитектуры, а не уговорами в системном промпте.
-
Маскирование персональных данных. Чувствительные данные выявляются специальными моделями и маскируются или шифруются до того, как попасть в контекст агента, в логи или во внешние API. Утечь они не должны нигде по пути.
-
Защита от prompt injection. Любой текст, попадающий в оркестратор — от пользователя, из читаемых документов, из ответов внешних API — фильтруется отдельной моделью на предмет инъекций и аномального поведения. Если что-то найдено — исполнение блокируется.
4. Human-in-the-loop — человек как последняя линия
Человека полностью убирать не стоит. Но и проверять каждое действие агента вручную — значит обнулить весь смысл автоматизации. Эскалация на человека должна срабатывать по чётким триггерам.
-
Критическое решение по регламенту. Списание крупной суммы, отмена транзакции, выдача персональных данных — всё, что заранее помечено в протоколе как требующее ручного подтверждения, идёт на человека независимо от уверенности агента.
-
Guardrail сомневается. Если LLM-критик не уверен в качестве ответа или подозревает, что агент зашёл в тупик и крутится по кругу — кейс уходит оператору, не дожидаясь, пока агент сам себя сломает.
-
Сам агент просит помощи. У вашего агента может быть отдельный тул “спросить человека”. Если в ходе работы он обнаруживает ситуацию, которая выходит за рамки регламента, — он не пытается домыслить, а останавливается и спрашивает.
Все четыре уровня работают вместе. Observability показывает, что происходит. Guardrails не дают плохим ответам уйти в прод. Барьеры безопасности ограничивают радиус возможных проблем. Human-in-the-loop ловит самые сложные кейсы.
Заключение
Подведём итог. Берите процессы с большим эффектом, чистым intelligence и приемлемым риском — это первая половина успеха. Разрабатывайте через работу с контекстом, проходите три стадии последовательно, стройте контур контроля пропорционально автономности и риску, который на себя взяли. Тогда вы уже будете в 5% тех счастливчиков, что не застревают в бесконечных презентациях и пилотах.
Но главное, о чём не стоит забывать: самая большая инвестиция, которую вы только можете сделать — это не модели и не железо, а экспертиза вашей команды. Развивайте её внутри, не пытайтесь всё купить на стороне. Внедрение AI — это про плотную интеграцию технологии и вашего бизнеса, такую тесную связку можно только вырастить внутри. Начинайте с проектов, у которых есть реальный шанс состояться — пусть не самых эффектных, но таких, на которых команда наберёт опыт. Следующий проект пройдёт в разы быстрее. Прошу прощения за пошлое сравнение, но AI — это не спринт, а марафон.
Если поcле прочтения остались вопросы по разработке агентов — пишите в личные сообщения. Вместе разберёмся.